Relaciones en Bases de Datos NoSQL: ¿Embeber o Referenciar? Una Guía Técnica para la Toma de Decisiones
- Mauricio ECR
- Persistencia
- 27 Apr, 2025
El auge de las bases de datos NoSQL ha redefinido la manera en que abordamos el modelado de datos, ofreciendo flexibilidad y escalabilidad que a menudo superan las limitaciones de los modelos relacionales tradicionales. Sin embargo, esta libertad conlleva nuevas consideraciones, especialmente a la hora de definir las relaciones entre las entidades de nuestra aplicación. A diferencia de las claves foráneas y las uniones explícitas de las bases de datos SQL, en el mundo NoSQL (particularmente en las bases de datos orientadas a documentos), debemos decidir entre embeber documentos relacionados dentro de un documento principal o referenciar documentos a través de identificadores.
Esta decisión no es trivial y tiene un impacto profundo en el rendimiento, la escalabilidad, la consistencia y la complejidad de nuestra aplicación. Este artículo profundiza en los factores clave a considerar al tomar esta elección crítica, proporcionando una base sólida para arquitectos y desarrolladores de software que trabajan con bases de datos NoSQL.
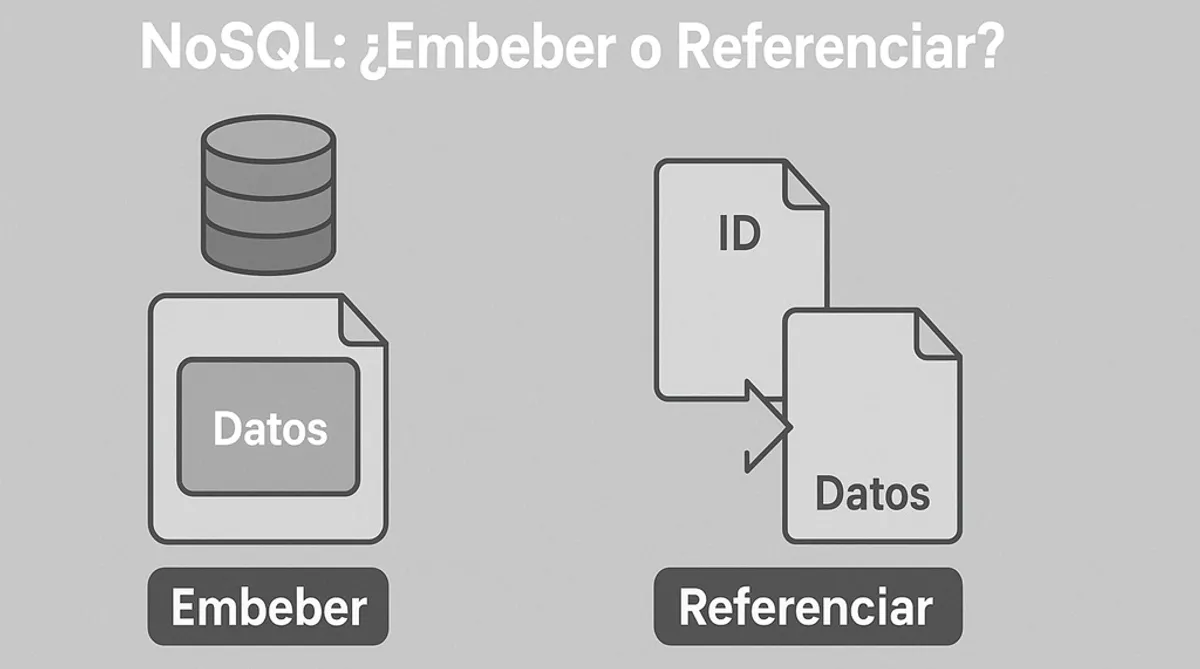
Embeber Documentos: Consolidación para el Acceso Rápido
Embeber (embedding) implica anidar un documento dentro de otro. En este modelo, la información relacionada se almacena físicamente junta en un único documento.
Ventajas:
- Mejor rendimiento de lectura: Almacenar datos relacionados juntos permite recuperarlos en una sola operación de lectura, eliminando la necesidad de múltiples consultas o “joins” a nivel de aplicación o base de datos. Esto es ideal para escenarios donde los datos relacionados se acceden con mucha frecuencia junto con el documento principal.
- Operaciones atómicas: Las actualizaciones a los datos dentro de un único documento embebido suelen ser atómicas, lo que garantiza que las operaciones se completen por completo o no se realicen en absoluto, simplificando la lógica de manejo de concurrencia para esos datos específicos.
- Menor complejidad de consultas simples: Para patrones de acceso que siempre recuperan el documento principal y sus relacionados, la consulta es directa y sencilla.
Desventajas:
- Duplicación de datos: Si un documento embebido necesita aparecer en múltiples documentos principales, la información se duplicará, lo que puede llevar a inconsistencias si los datos embebidos cambian.
- Tamaño del documento: Embeber grandes cantidades de datos o datos que crecen sin límites puede aumentar significativamente el tamaño de los documentos. Esto puede impactar el rendimiento de lectura y escritura, y muchas bases de datos NoSQL tienen límites en el tamaño máximo de un documento (por ejemplo, 16 MB en MongoDB).
- Complejidad en actualizaciones frecuentes o parciales: Si los datos embebidos cambian con mucha frecuencia o si solo se necesita actualizar una pequeña parte de ellos, modificar el documento principal completo puede ser ineficiente.
- Dificultad para consultar datos embebidos de forma independiente: Consultar o agregar datos basándose únicamente en la información dentro de los documentos embebidos puede ser menos eficiente o más complejo que si estuvieran en una colección separada.
Referenciar Documentos: Flexibilidad y Normalización Controlada
Referenciar (referencing) implica almacenar documentos relacionados en colecciones separadas y utilizar identificadores (como el _id en MongoDB) en un documento para crear un enlace a otro. Este enfoque es más similar al concepto de claves foráneas en bases de datos relacionales.
Ventajas:
- Reduce la duplicación de datos: La información se almacena una sola vez en su propia colección, lo que simplifica la gestión de actualizaciones y reduce el riesgo de inconsistencia.
- Flexibilidad para consultar datos de forma independiente: Los documentos referenciados pueden ser consultados, actualizados y gestionados de forma independiente de los documentos que los referencian.
- Manejo eficiente de datos que crecen sin límites: Colecciones separadas son más adecuadas para almacenar grandes cantidades de datos o datos que se espera que crezcan considerablemente.
- Ideal para relaciones muchos-a-muchos: Las relaciones complejas donde múltiples documentos de una colección se relacionan con múltiples documentos de otra colección se manejan más naturalmente con referencias.
Desventajas:
- Mayor complejidad en la recuperación de datos relacionados: Para obtener el documento principal y sus relacionados, se requieren múltiples consultas (una para el documento principal y luego una o más para los documentos referenciados) o el uso de funcionalidades de “lookup” proporcionadas por la base de datos (si están disponibles), lo que puede aumentar la latencia de lectura.
- Falta de atomicidad en operaciones que involucran múltiples documentos: Las actualizaciones que afectan a datos en diferentes colecciones referenciadas no son atómicas por defecto, lo que requiere una lógica a nivel de aplicación o transacciones distribuidas (si la base de datos lo soporta) para garantizar la consistencia.
- Mayor complejidad en el modelo de datos para relaciones simples: Para relaciones uno-a-uno o uno-a-pocos, el modelo referenciado puede parecer más verboso que el modelo embebido.
Factores Clave para la Decisión
La elección entre embeber y referenciar depende en gran medida de los patrones de acceso a los datos y los requisitos de la aplicación. Aquí se detallan los factores más importantes a considerar:
-
Patrones de Acceso a Datos:
- Lectura intensiva y datos accedidos conjuntamente: Si los datos relacionados casi siempre se leen junto con el documento principal y las lecturas son mucho más frecuentes que las escrituras, embeber suele ofrecer un mejor rendimiento.
- Acceso independiente a datos relacionados: Si los datos relacionados se consultan o actualizan con frecuencia de forma independiente del documento principal, referenciar es la opción más eficiente.
- Necesidad de consultar y agregar datos relacionados por sí solos: Si se requiere realizar consultas o agregaciones complejas sobre los datos relacionados sin pasar por el documento principal, referenciar facilita estas operaciones.
-
Tamaño y Crecimiento de los Datos Relacionados:
- Datos relacionados pequeños y con crecimiento limitado: Embeber es viable si la cantidad de datos relacionados es pequeña y no se espera que crezca significativamente, manteniendo el tamaño total del documento dentro de límites razonables.
- Datos relacionados grandes o con crecimiento ilimitado: Referenciar es esencial cuando los datos relacionados pueden ser extensos (por ejemplo, una larga lista de comentarios o transacciones) para evitar exceder los límites de tamaño del documento y mantener un rendimiento de escritura eficiente.
-
Frecuencia y Naturaleza de las Actualizaciones:
- Actualizaciones frecuentes de datos embebidos: Si los datos que se considerarían para ser embebidos cambian muy a menudo, referenciar es preferible para evitar la sobrecarga de actualizar el documento principal constantemente.
- Actualizaciones atómicas requeridas para datos relacionados: Si un conjunto de datos relacionados debe actualizarse de manera atómica junto con el documento principal, embeber simplifica la implementación.
- Actualizaciones independientes de diferentes partes de los datos relacionados: Si distintos elementos dentro de los datos relacionados se actualizan de forma independiente y frecuente, referenciar permite actualizaciones más localizadas y eficientes.
-
Consistencia de los Datos:
- Alta prioridad en la consistencia global de los datos relacionados: Referenciar reduce la duplicación y simplifica la garantía de que las actualizaciones a los datos se reflejen consistentemente en toda la base de datos.
- Consistencia eventual aceptable para datos embebidos: Si una ligera inconsistencia temporal es tolerable para los datos embebidos (por ejemplo, la información duplicada tarda un corto tiempo en sincronizarse si cambia el original referenciado en otro lugar), embeber puede ser aceptable.
-
Complejidad del Esquema y las Relaciones:
- Relaciones uno-a-uno y uno-a-pocos contenidas: Embeber a menudo resulta en un esquema más simple y consultas directas para estas relaciones, especialmente cuando los “pocos” son realmente pocos y su crecimiento es limitado.
- Relaciones uno-a-muchos y muchos-a-muchos: Referenciar es generalmente la opción más escalable y manejable para estas relaciones, evitando documentos excesivamente grandes o la complejidad de manejar listas potencialmente ilimitadas dentro de un documento.
-
Consideraciones Específicas de la Base de Datos NoSQL:
- Aunque los principios generales son aplicables, las características específicas de la base de datos NoSQL utilizada (MongoDB, Cassandra, Couchbase, etc.) pueden influir en la decisión. Por ejemplo, las capacidades de “lookup” o las limitaciones de tamaño de documento varían entre bases de datos.
Un Enfoque Híbrido
Es importante destacar que no siempre es una elección binaria entre embeber o referenciar. En muchos casos, un enfoque híbrido puede ser la solución óptima. Esto implica embeber los datos relacionados que se acceden con mucha frecuencia y que tienen un tamaño limitado, mientras se referencian otros datos relacionados que son más grandes, cambian con frecuencia o se consultan de forma independiente.
Por ejemplo, en un documento de “pedido”, se podría embeber una lista de “ítems del pedido” (si la lista no es excesivamente larga y se accede siempre con el pedido), pero referenciar el documento de “cliente” y los documentos de “productos” para evitar duplicar información del cliente o los detalles completos de cada producto en cada pedido.
Conclusión
La decisión de si embeber o referenciar datos en una base de datos NoSQL es un pilar fundamental en el diseño de esquemas eficientes y escalables. No existe una regla única para todos los casos; la elección debe basarse en una comprensión profunda de los patrones de acceso a datos de la aplicación, los requisitos de rendimiento, las expectativas de crecimiento de los datos y las características específicas de la base de datos NoSQL empleada.
Embeber favorece el rendimiento de lectura y la atomicidad para datos accedidos conjuntamente y de tamaño limitado. Referenciar ofrece flexibilidad, reduce la duplicación y es más adecuado para datos grandes, de crecimiento ilimitado, que cambian con frecuencia o que participan en relaciones complejas. Un enfoque híbrido a menudo permite capitalizar las ventajas de ambos modelos.
Una evaluación cuidadosa de los factores discutidos y la posibilidad de realizar pruebas de rendimiento con diferentes modelos de datos son pasos cruciales para asegurar que el diseño de la base de datos NoSQL soporte eficazmente las necesidades actuales y futuras de la aplicación. La continua monitorización y adaptación del esquema a medida que evolucionan los patrones de uso también son prácticas recomendadas en el dinámico entorno NoSQL.
A continuación, se presenta un diagrama de decisión simplificado para visualizar el proceso de elección entre embeber y referenciar:

codigo mermaid
graph TD
A[Iniciar: Modelando Relaciones NoSQL] --> B{Datos relacionados accedidos
principalmente con el padre?}
B -->|Sí| C{Datos relacionados pequeños
y con crecimiento limitado?}
C -->|Sí| D{Actualizaciones frecuentes
de datos relacionados?}
D -->|No| E[Embeber]
D -->|Sí| F{Consistencia global alta prioridad?}
F -->|Sí| G[Referenciar]
F -->|No| E
C -->|No| H{Datos relacionados grandes
o crecimiento ilimitado?}
H -->|Sí| G
H -->|No| I{Relación muchos-a-muchos?}
I -->|Sí| G
I -->|No| J{Necesidad de consultar/actualizar
datos relacionados independientemente?}
J -->|Sí| G
J -->|No| E
B -->|No| K{Datos relacionados consultados/actualizados
frecuentemente de forma independiente?}
K -->|Sí| G
K -->|No| I
E --> L[Implementar modelo embebido]
G --> M[Implementar modelo referenciado]
L --> N[Fin]
M --> N[Fin]