Observabilidad sin Ruido: Diseñando un Sistema de Logs con AOP en Arquitecturas DDD
- Mauricio ECR
- Arquitectura
- 01 Mar, 2026
Hay una tensión que todo equipo de desarrollo enfrenta tarde o temprano: la necesidad de saber qué está pasando dentro del sistema sin que esa necesidad contamine el código que lo hace funcionar. Los logs son la herramienta más inmediata para satisfacer esa necesidad, pero también son, cuando no se gestionan con criterio, una de las fuentes más frecuentes de deuda técnica, acoplamiento silencioso y dolores de cabeza en producción.
Lo que se propone en este artículo es un modelo de observabilidad para sistemas construidos con Java 21, Spring Boot 3.5.x, Gradle y arquitectura DDD. El objetivo no es solo definir dónde va cada logger.info(), sino construir un esquema en el que la observabilidad sea una preocupación transversal completamente separada de la lógica de negocio, implementada mediante Programación Orientada a Aspectos (AOP) y sostenida por convenciones que cualquier miembro del equipo pueda seguir sin ambigüedad.
El problema que queremos resolver
Antes de hablar de la solución vale la pena entender con precisión el problema. En la mayoría de los proyectos, los logs nacen de forma orgánica: el desarrollador que escribe un caso de uso añade un par de líneas de debug para entender qué está pasando durante el desarrollo, y esas líneas se quedan ahí. Llega otro desarrollador, añade las suyas, y así sucesivamente. El resultado, algunos meses después, es un codebase donde la lógica de negocio está entrelazada con instrucciones de log que nadie revisa, que no siguen ningún formato consistente, que en algunos métodos son excesivas y en otros brillan por su ausencia, y que en más de una ocasión exponen datos sensibles de los usuarios en texto plano.
El problema no es que los desarrolladores sean descuidados. El problema es estructural: cuando la responsabilidad de loguear está distribuida en cada clase del sistema, es inevitable que el resultado sea inconsistente. La única forma de garantizar consistencia es centralizar esa responsabilidad en un mecanismo que opere de forma transversal, sin depender de que cada desarrollador recuerde seguir una convención.
Eso es, en esencia, lo que ofrece la Programación Orientada a Aspectos.
AOP: observar sin intervenir
La idea central de AOP es simple aunque su implementación puede ser sofisticada: existen preocupaciones en un sistema, como la seguridad, las transacciones o el logging, que no pertenecen a ningún módulo en particular pero que afectan a todos. En lugar de dispersar el código que gestiona esas preocupaciones por todo el sistema, AOP permite encapsularlo en un componente separado llamado aspecto, que el framework inyecta de forma transparente en los puntos de ejecución que se le indiquen.
En el contexto de Spring, esto funciona a través de proxies. Cuando el contenedor de inversión de control crea un bean, puede envolverlo en un proxy que intercepta las llamadas a sus métodos. Ese proxy ejecuta el aspecto antes, después o alrededor de la llamada real. El método original no sabe que está siendo observado; simplemente hace su trabajo.
Para que este mecanismo funcione hay una condición que no siempre es obvia: los objetos deben ser beans de Spring. Si una clase no está gestionada por el contenedor, Spring no puede envolverla en un proxy y el aspecto no puede interceptarla. Este detalle tiene una implicación directa en cómo se diseña la observabilidad en una arquitectura DDD, y es precisamente el punto de partida para resolver uno de los dilemas más frecuentes en este tipo de proyectos.
La capa de dominio y el dilema del logging
En una arquitectura DDD estricta, la capa de dominio es la más interna y la más pura. No debe tener dependencias de infraestructura, no debe saber si está siendo ejecutada en una API REST o en un job batch, y definitivamente no debería importar librerías de logging. Esta pureza es lo que la hace testeable, portable y mantenible.
Pero esa misma pureza genera una pregunta legítima: ¿qué pasa con los servicios de dominio? Un servicio que valida si un cliente tiene crédito suficiente, que aplica reglas de descuento, que verifica el stock disponible, ¿no merece ser observado? Si algo falla en esa lógica, ¿cómo sabremos qué ocurrió?
La respuesta convencional suele ser una de dos: o se acepta contaminar el dominio con un logger, o se ignora completamente ese nivel de detalle y se espera que las excepciones cuenten la historia. Ninguna de las dos opciones es satisfactoria.
La salida está en un detalle de implementación que a veces pasa desapercibido: cuando los servicios de dominio y los casos de uso se registran como beans en el contenedor de Spring a través de la capa de aplicación, aunque el dominio no sabe nada de Spring, el contenedor sí los gestiona. Y si el contenedor los gestiona, AOP puede interceptarlos. El dominio sigue siendo puro porque no tiene ninguna dependencia en infraestructura. El aspecto lo observa desde afuera, a través del proxy, sin que el servicio de dominio sea consciente de ello.
Este es uno de esos casos donde las restricciones de una arquitectura, entendidas a fondo, abren posibilidades que no eran evidentes a primera vista.
Una sola responsabilidad por capa
Con ese fundamento claro, los puntos de observabilidad se organizan siguiendo la misma lógica que organiza la arquitectura: cada capa tiene su propio contrato de logging.
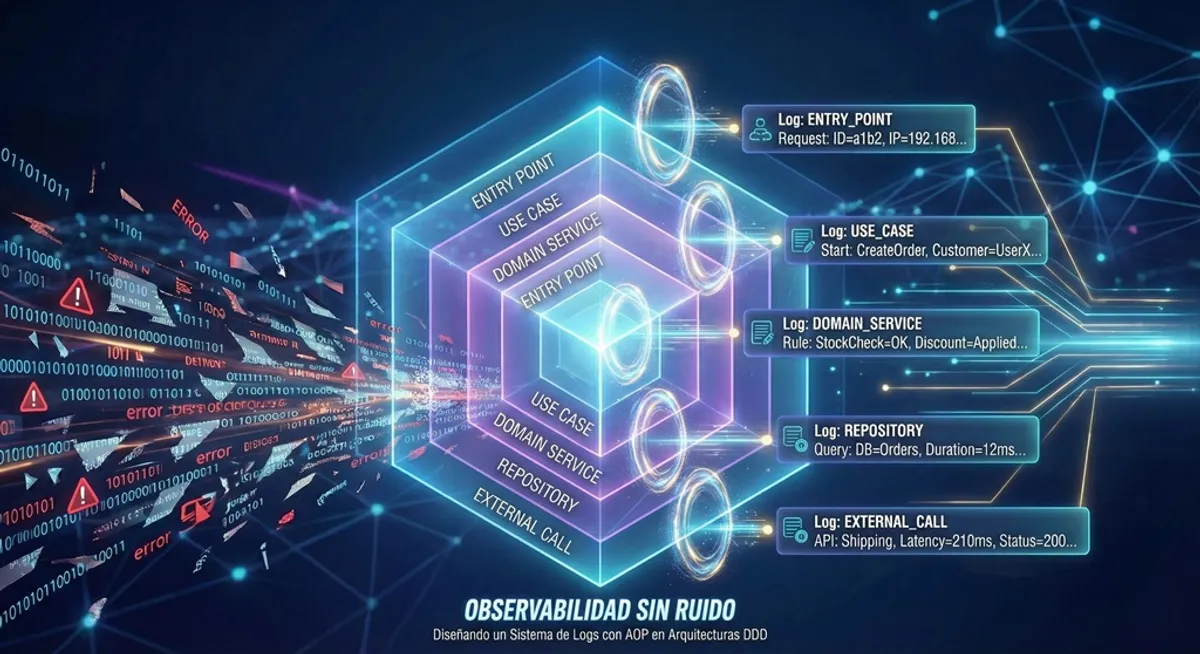
Los entry points, que son los controladores REST o cualquier otro mecanismo de entrada al sistema, son el primer y último punto que el aspecto intercepta en el flujo de una solicitud. Aquí se registra el request entrante con los datos de entrada saneados y, cuando el flujo termina, el response saliente con el tiempo total que tomó la operación. Es la vista más amplia del sistema: saber qué llegó y qué salió.
Los casos de uso aportan el siguiente nivel de granularidad. El aspecto registra el inicio y el fin de la orquestación, con el DTO de entrada ya mapeado y el resultado antes de que sea transformado para la respuesta. Esto permite correlacionar exactamente qué datos entran al corazón del sistema y qué produce como resultado.
Los servicios de dominio representan el nivel más detallado. Aquí el aspecto registra el resultado de cada validación, cada regla de negocio, cada decisión que toma el dominio. Este nivel de detalle, sin embargo, no necesita estar activo permanentemente en producción. Se emite en nivel DEBUG, lo que significa que en un ambiente productivo es invisible pero puede activarse dinámicamente en cuestión de segundos si se necesita diagnosticar un problema sin reiniciar la aplicación.
Finalmente, los driven adapters, que son las implementaciones de los puertos hacia el mundo exterior, tienen un requerimiento adicional que los diferencia de todas las demás capas: la latencia. No basta con saber que se hizo una llamada a un servicio externo o que se ejecutó una consulta a la base de datos; hay que saber cuánto tardó. Esa información es la que permite distinguir entre un problema de lógica interna y un problema de dependencia externa, una diferencia que en producción puede significar horas de diagnóstico incorrecto.
El tiempo como dato de primera clase
Medir el tiempo solo en las llamadas externas es un primer paso, pero insuficiente. Para entender verdaderamente el comportamiento de un sistema bajo carga es necesario conocer cuánto tarda cada etapa del flujo. Un total de 800 milisegundos en una solicitud puede ser perfectamente aceptable o completamente inaceptable dependiendo de dónde se origina ese tiempo.
Por eso cada punto de observabilidad debe registrar dos métricas de tiempo: durationMs, que mide cuánto tardó esa etapa específica, y elapsedMs, que mide el tiempo acumulado desde que llegó la solicitud hasta ese punto. Con ambas métricas en cada registro, reconstruir la línea de tiempo de una transacción en una herramienta de observabilidad es trivial.
A esto se suma un campo stage en cada registro, que identifica la capa que lo generó: ENTRY_POINT, USE_CASE, DOMAIN_SERVICE, EXTERNAL_CALL o REPOSITORY. Este campo convierte los logs de texto plano en datos estructurados sobre los que se pueden construir dashboards, alertas y análisis de performance sin necesidad de parsear mensajes de texto.
El valor de este diseño se hace evidente con un ejemplo concreto. Imaginemos una solicitud de creación de orden de compra que tarda 800 milisegundos en total. Sin el campo stage y sin durationMs por etapa, la única conclusión disponible es que la solicitud fue lenta. Con esos campos, el análisis revela en segundos que 600 de esos 800 milisegundos los consumió la API externa de cobertura logística, mientras que la lógica de dominio tomó menos de 15 milisegundos. La optimización correcta es evidente: no hay que tocar el dominio, hay que atacar la dependencia externa.
Privacidad por diseño, no por convención
Uno de los aspectos más delicados del logging es la privacidad. Cada vez que un sistema registra información existe el riesgo de que datos sensibles terminen en un archivo de log, en una herramienta de indexación o en el radar de una auditoría de seguridad. La respuesta habitual a este riesgo es la convención: “no logueen datos personales”. El problema con las convenciones es que dependen de que cada desarrollador las recuerde y las aplique correctamente en cada caso.
Un enfoque más robusto es que la privacidad se declare en el modelo de datos, no en el código que loguea.
Para materializar esto se definen dos anotaciones que se aplican directamente sobre los campos del modelo de dominio. La primera, @NoLog, indica que un campo nunca debe aparecer en ningún log bajo ninguna circunstancia: omisión total. Se usa para campos como imágenes en Base64, documentos adjuntos, o cualquier objeto cuyo tamaño o naturaleza lo hace inadecuado para un registro. La segunda, @Confidential, indica que el campo contiene datos personales y que su valor debe enmascararse antes de escribirse. El aspecto aplica una función de máscara según el tipo configurado: una dirección de correo como [email protected] se convierte en j***@mail.com, un número de identificación se convierte en ***, un teléfono muestra solo los últimos cuatro dígitos.
Lo elegante de este diseño es que las reglas de privacidad viven donde tienen sentido: en el modelo de dominio, junto a la definición del dato. Cuando un desarrollador crea un campo en un modelo y lo anota con @Confidential, esa anotación se respeta automáticamente en todos los logs del sistema, sin necesidad de recordar actualizar ningún otro componente. La privacidad deja de ser una convención y se convierte en una propiedad del dato.
Más allá de las anotaciones, hay categorías de información que nunca deben aparecer en logs independientemente de si están anotadas: credenciales, tokens de autenticación, datos completos de tarjetas de crédito, cookies de sesión, datos biométricos. La regla práctica que sintetiza todos estos casos es directa: si el dato permite suplantar la identidad de un usuario o acceder a un sistema, no va en el log.
Trazabilidad: el hilo que conecta todo
Un log aislado tiene valor limitado. El valor real emerge cuando se pueden correlacionar todos los eventos de una transacción, desde que llega la solicitud hasta que sale la respuesta, incluyendo cada llamada externa y cada decisión de dominio que ocurrió en el camino.
El mecanismo que hace posible esta correlación es el message-id, un identificador único que se asigna a cada solicitud en el momento en que entra al sistema. Si el cliente lo envía en el header X-Message-Id, se reutiliza; si no viene, el sistema genera uno automáticamente. Este identificador se almacena en el MDC de SLF4J, que es un mapa de contexto asociado al hilo de ejecución. Todos los logs emitidos durante esa solicitud lo incluyen automáticamente.
El resultado es que en cualquier herramienta de observabilidad, filtrar por message-id produce exactamente la secuencia completa de eventos de una transacción, ordenada por tiempo, con cada etapa identificada por su stage y con sus métricas de duración. Lo que antes requería correlacionar manualmente decenas de líneas de log dispersas ahora es una consulta de una sola condición.
Este mecanismo presenta un desafío particular en operaciones asíncronas. Cuando Spring lanza un hilo para ejecutar una tarea marcada con @Async, ese hilo nuevo no hereda el MDC del hilo padre. El message-id y el tiempo de inicio de la solicitud se pierden, y los logs del hilo asíncrono quedan huérfanos sin correlación. La solución es un decorador de tareas que captura el MDC completo del hilo padre en el momento en que se lanza la tarea y lo restaura en el hilo hijo antes de ejecutarla. Este decorador se configura una sola vez en el executor del pool de hilos y aplica a todas las operaciones asíncronas del sistema sin ningún esfuerzo adicional por parte del desarrollador.
El mismo principio se extiende a arquitecturas de microservicios. Cuando el sistema hace una llamada HTTP a otro servicio, el message-id debe viajar en el header de la petición saliente. El microservicio receptor lo extrae, lo almacena en su propio MDC, y todos sus logs quedan correlacionados con la misma transacción origen. Esto se configura una sola vez en el cliente HTTP como un interceptor, y a partir de ahí todas las llamadas salientes propagan el identificador automáticamente. En una plataforma de observabilidad centralizada, una sola búsqueda por message-id puede reconstruir el árbol completo de llamadas entre servicios.
El flujo completo bajo la lupa
Para ilustrar cómo se manifiesta todo esto en la práctica, vale la pena recorrer un flujo real. Tomemos la creación de una orden de compra como caso de uso: el cliente envía los datos de la orden con sus productos, dirección de entrega e información personal; el sistema valida que el cliente esté activo, verifica el stock, homologa los códigos externos de los productos a los códigos internos del catálogo, consulta una API externa para validar la cobertura logística en la dirección indicada, persiste la orden en base de datos y devuelve el número de orden generado.
Sin escribir una sola línea de log en ninguno de esos componentes, el aspecto genera automáticamente doce registros a lo largo del flujo. El primero captura el request entrante con los datos saneados: el correo del cliente enmascarado, el número de identificación reemplazado por asteriscos, los documentos adjuntos simplemente omitidos. El segundo marca el inicio del caso de uso. Los registros tres, cuatro y cinco corresponden a los servicios de dominio: la validación del cliente, la validación de stock y la homologación de productos; estos se emiten en DEBUG y son invisibles en producción a menos que se activen dinámicamente. Los registros siete y ocho capturan la llamada a la API de cobertura logística con su latencia exacta. Los registros nueve y diez hacen lo mismo con la operación de base de datos. El registro once cierra el caso de uso con el tiempo total de orquestación. El doce emite el response saliente con el tiempo total de la solicitud de punta a punta.
El análisis de esos doce registros revela de inmediato la distribución del tiempo: cuatro milisegundos de overhead en los mappers de entrada, diez milisegundos en validaciones de dominio, doscientos diez milisegundos en la API de cobertura logística, cuarenta y cinco milisegundos en base de datos. Sin ningún profiler, sin instrumentación adicional, el sistema cuenta su propia historia con precisión quirúrgica.
El mismo flujo en un escenario de error muestra otra dimensión del diseño. Si el stock es insuficiente, el servicio de dominio lanza una excepción de negocio controlada. El aspecto la captura a nivel DEBUG en el servicio de dominio y la deja subir. El @ControllerAdvice la intercepta y emite un registro en nivel WARN, no ERROR, porque una validación fallida es una condición esperada del negocio, no un fallo del sistema. Sin stacktrace completo, solo el mensaje de negocio y el message-id. En cambio, si la API externa de cobertura logística devuelve un timeout, el adapter emite un registro en nivel ERROR con stacktrace completo y la latencia exacta que revela los cinco segundos de espera antes del fallo.
Esta distinción entre WARN y ERROR no es cosmética. En los dashboards de monitoreo permite separar el ruido normal del negocio de los fallos reales que requieren atención inmediata. Un equipo de operaciones que recibe alertas solo para registros ERROR puede confiar en que cada alerta representa un problema genuino del sistema, no una validación fallida que el usuario debe corregir.
Producción sin sorpresas
Hay un escenario que todo sistema productivo enfrenta eventualmente: un comportamiento anómalo que no se reproduce en desarrollo y que requiere ver el detalle de la lógica interna para diagnosticarse. En el modelo tradicional, la respuesta a este escenario era subir el nivel de log a DEBUG, redesplegar, esperar, bajar el nivel, redesplegar de nuevo. Un proceso lento, arriesgado y que en sistemas con tráfico real puede generar un volumen de logs suficiente para saturar la infraestructura de observabilidad.
Dos mecanismos complementarios evitan ese ciclo. El primero es la jerarquía de niveles ya descrita: los logs de DOMAIN_SERVICE se emiten en DEBUG, así que en producción con nivel INFO son completamente invisibles y no generan ningún costo operativo. El segundo es el cambio dinámico de nivel a través de un endpoint interno que delega en la API de loggers de Spring Boot Actuator. Activar DEBUG para un paquete específico, observar el comportamiento, y volver a INFO es una operación de segundos sin ningún redespliegue.
Este diseño refleja una filosofía más amplia: las herramientas de observabilidad deben poder adaptarse al momento sin modificar el sistema observado.
Lo que también importa, aunque no se vea en el código
Hay una dimensión del logging que no suele documentarse pero que es igualmente crítica: saber qué no loguear. Las anotaciones @NoLog y @Confidential cubren los datos que el modelo declara explícitamente como sensibles, pero hay categorías de información que nunca deben aparecer en logs independientemente de cualquier anotación.
Los tokens de autenticación son el ejemplo más obvio. Un JWT completo, una API key o un refresh token en un log es esencialmente una credencial expuesta que puede ser extraída por cualquiera con acceso a la plataforma de observabilidad, que en muchas organizaciones incluye a un número considerable de personas. Lo mismo aplica para contraseñas, PINs, datos completos de tarjetas de crédito, cookies de sesión y datos biométricos.
La lista no es exhaustiva ni puede serlo, porque los datos sensibles dependen del contexto de cada sistema. Lo que sí puede establecerse como hábito es hacerse la pregunta antes de que un dato llegue a un registro. Y en la duda, la respuesta correcta es siempre la omisión.
De los logs a la inteligencia operacional
Un sistema de logs bien diseñado no es solo un mecanismo de diagnóstico reactivo. Es la materia prima de la inteligencia operacional. Los campos estructurados que este esquema produce, stage, durationMs, elapsedMs, event, adapter, permiten derivar métricas sin instrumentación adicional en el código.
La latencia promedio por adapter externo permite monitorear el SLA de cada dependencia. La tasa de registros con event=BUSINESS_EXCEPTION agrupada por tipo de excepción permite entender qué reglas de negocio fallan con más frecuencia y orientar decisiones de producto. El tiempo total por endpoint permite construir alertas que disparen cuando la latencia supera el percentil 99 histórico. La correlación entre EXTERNAL_CALL_START sin su correspondiente EXTERNAL_CALL_END permite detectar llamadas que nunca respondieron.
Y quizás el beneficio más silencioso de todos: cada nueva funcionalidad que se añada al sistema hereda automáticamente la observabilidad con el mismo nivel de detalle y el mismo formato estructurado, simplemente por seguir la arquitectura. No hay nada que recordar, nada que configurar, nada que pueda olvidarse.
Mirando hacia adelante
Lo descrito en este artículo establece una base sólida, pero no es un punto de llegada. Hay líneas de evolución naturales que vale la pena tener en el horizonte.
La integración con sistemas de tracing distribuido como OpenTelemetry lleva la correlación entre microservicios un paso más allá, al construir árboles de spans que representan visualmente la jerarquía de llamadas, con tiempos y metadatos, en una interfaz diseñada específicamente para ese propósito. Los logs estructurados que produce este esquema son compatibles con ese modelo y pueden complementarlo sin contradicción.
La generación automática de métricas de aplicación a través de Micrometer desde los mismos puntos de intercepción del AOP es otra extensión natural, ya que evita la duplicación entre el sistema de logs y el sistema de métricas, manteniendo una única fuente de verdad para ambos tipos de datos.
El mismo patrón de aspectos transversales también puede extenderse a otros dominios de preocupación: auditoría de cambios de estado, registro de accesos a datos sensibles para cumplimiento regulatorio, o validación automática de contratos entre capas.
Lo que todo esto ilustra, más allá de los detalles técnicos, es que la observabilidad no tiene por qué ser un ciudadano de segunda clase en la arquitectura de un sistema. Cuando se diseña con la misma intención que se diseña la lógica de negocio, cuando se le aplican los mismos principios de separación de responsabilidades y consistencia, se convierte en una ventaja operacional genuina: el equipo gana la capacidad de entender qué está pasando en producción en cualquier momento, con el nivel de detalle que necesita, sin adivinar y sin contaminar el código que hace que el sistema funcione.
La implementación concreta de este diseño, con el código de cada artefacto, los aspectos completos, el sanitizador de datos y el ejemplo funcional del flujo de orden de compra, se documenta en detalle en la segunda parte de este artículo.




























