Arquitectura Modular por Contexto: Cuando la Teoría se Encuentra con la Realidad
- Mauricio ECR
- Arquitectura
- 21 Mar, 2026
Has estado ahí. Es lunes por la mañana, abres el proyecto en tu IDE, y necesitas modificar cómo se procesa un pedido. Treinta minutos después, todavía estás navegando entre carpetas intentando encontrar todas las piezas del rompecabezas. El caso de uso está en algún lugar del módulo de dominio, el controlador REST disperso en los entry points, el adaptador de base de datos perdido en persistencia, y probablemente algunos DTOs compartidos en carpetas que juraste que recordarías. Este es el dilema que enfrentamos constantemente: las herramientas que usamos nos imponen una estructura técnica impecable, pero nuestro cerebro humano necesita algo diferente. Necesitamos que todo lo relacionado con “procesar un pedido” esté junto, fácil de encontrar, fácil de entender, fácil de modificar.
La Estructura que las Herramientas Imponen
Para entender el problema, primero necesitamos entender cómo funcionan las herramientas de scaffolding modernas, particularmente Scaffolding of Clean Architecture—una herramienta que muchas organizaciones adoptan porque estandariza proyectos y acelera su inicio. Esta herramienta genera automáticamente una estructura basada en Clean Architecture, pero con una característica particular: todo se organiza estrictamente por naturaleza técnica a través de módulos independientes de Gradle. No son simples carpetas; son módulos que se compilan independientemente, gestionan sus propias dependencias, y establecen fronteras arquitectónicas reales. La estructura generada típicamente incluye: Un módulo de dominio completamente independiente, sin dependencias hacia otros módulos del proyecto. Aquí viven las entidades, los casos de uso, los servicios de dominio, y crucialmente, las interfaces (gateways) que definen qué operaciones necesita el dominio sin especificar cómo se implementan. Es el núcleo puro de la lógica de negocio. Un módulo de infraestructura que se subdivide en dos grandes grupos. Por un lado, los “driven adapters”—módulos para implementar persistencia (jpa-repository), para consumir servicios externos (rest-consumer), para publicar mensajes (message-sender), y otros adaptadores que implementan los contratos que el dominio define. Por otro lado, los “entry points”—módulos para exponer APIs REST (api-rest), para consumir eventos (message-listener), para tareas programadas (scheduled-task), y otros puntos de entrada al sistema. Un módulo de aplicación que ensambla todo, conteniendo la configuración que conecta las piezas, los aspectos transversales como logging y auditoría, y el punto de arranque que levanta el sistema. Desde una perspectiva arquitectónica pura, es hermoso. Inversión de dependencias impecable: el dominio define contratos, la infraestructura los implementa. Separación clara de responsabilidades: cada módulo tiene su propósito bien definido. Fronteras forzadas por el sistema de build: no puedes violar accidentalmente las dependencias porque Gradle simplemente no compilará.
El Problema que Nadie Quiere Admitir
Pero entonces llega el día a día del desarrollo, y la fricción se hace evidente.
Necesitas implementar una nueva funcionalidad: registrar un usuario. Ejecutas el comando de scaffolding para generar el caso de uso. La herramienta lo crea en domain/usecase/ en una estructura genérica. Ejecutas otro comando para generar el entry point REST. Se crea en infrastructure/entry-points/api-rest/ en otra ubicación genérica. Necesitas persistencia, ejecutas el comando para generar el adaptador JPA. Aparece en infrastructure/driven-adapters/jpa-repository/ en su propia ubicación técnica.
Cada componente vive exactamente donde debe vivir según su naturaleza técnica. El problema es que conceptualmente todos estos componentes están relacionados—todos son parte de “registrar un usuario”—pero físicamente están dispersos por toda la estructura del proyecto según su clasificación técnica.
El resultado es predecible: cinco pestañas abiertas en tu IDE, navegación constante entre módulos y carpetas, DTOs compartidos en ubicaciones centralizadas que sirven a múltiples propósitos, validadores reutilizables que intentan ser genéricos, y mappers comunes que traducen entre representaciones para varios casos de uso.
Y hay algo peor: seis meses después, cuando otro desarrollador necesita modificar esa funcionalidad de registro de usuarios, el proceso se repite. Buscar, navegar, intentar recordar dónde quedaron todas las piezas dispersas. El conocimiento está fragmentado, la comprensión es difícil, y cada modificación se siente como resolver un rompecabezas.
La pregunta natural surge: ¿por qué no simplemente abandonar esta estructura modular y volver a algo más simple donde todo esté junto? Porque entonces perdemos beneficios reales que los módulos independientes proporcionan: compilación incremental que solo recompila lo que cambió, gestión explícita de dependencias que previene acoplamiento accidental, y fronteras arquitectónicas forzadas que mantienen la integridad del diseño a largo plazo.
O podrías pensar: ¿por qué no compartir más componentes entre funcionalidades? Crear carpetas centralizadas de DTOs reutilizables, validadores comunes, mapeadores genéricos. Suena eficiente hasta que dos funcionalidades que comparten un validador divergen en sus necesidades. Entonces enfrentas la decisión imposible: ¿modificas el validador compartido arriesgando romper la otra funcionalidad, o duplicas el código que justamente intentabas evitar?
La Solución Está en la Dualidad
La respuesta no está en elegir entre estructura técnica o cohesión conceptual. La respuesta está en reconocer que ambas son valiosas pero en diferentes niveles.
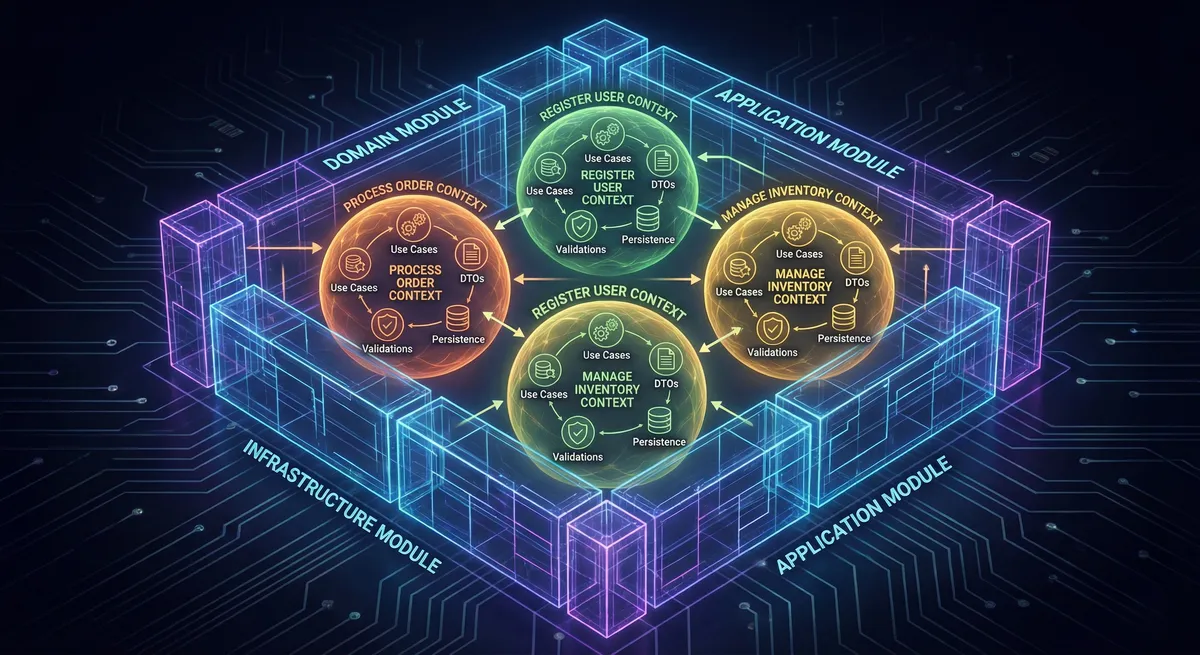
Imagina mantener la estructura de módulos técnicos que Scaffolding of Clean Architecture genera—porque proporciona beneficios arquitectónicos reales—pero cambiar radicalmente cómo organizas el código dentro de cada módulo. En lugar de estructuras técnicas genéricas donde todos los componentes del mismo tipo conviven en carpetas planas, organizas por contextos de negocio donde cada funcionalidad tiene su propio espacio autocontenido.
El módulo de dominio sigue siendo un módulo de dominio, pero cuando lo abres, en lugar de encontrar una carpeta usecase/ con cincuenta casos de uso en una lista plana, encuentras algo diferente. Cada caso de uso vive en su propia carpeta de contexto: usecase/registrar-usuario/, usecase/procesar-pedido/, usecase/consultar-inventario/. Cada contexto agrupa todo lo que esa funcionalidad específica necesita.
Dentro de registrar-usuario/ no solo está el archivo del caso de uso. Está su carpeta dto/ con los DTOs de entrada y salida diseñados exactamente para lo que este caso de uso necesita—no DTOs genéricos compartidos que intentan servir múltiples propósitos. Está su carpeta mapper/ con traductores que mapean precisamente entre las representaciones que este caso de uso maneja. Está su carpeta validator/ con validadores que aplican las reglas específicas de negocio de registrar usuarios. Si necesita enriquecer datos desde otras fuentes, tiene su carpeta enricher/. Si requiere utilidades especializadas, tiene su carpeta util/.
Todo junto. Todo cohesivo. Todo autocontenido.
Lo mismo sucede en el módulo de entry points. En lugar de una carpeta genérica api-rest/ con todos los controladores mezclados, encuentras api-rest/registrar-usuario-api/ como su propio contexto. Dentro están los DTOs específicos de la API REST—diferentes de los DTOs del caso de uso porque representan el contrato externo, no el contrato de dominio. Están los mapeadores que traducen entre el mundo HTTP y el mundo del dominio. Están los validadores específicos de la capa de presentación que verifican formatos y restricciones del protocolo.
Y en el módulo de adaptadores, en lugar de entidades JPA genéricas en una carpeta común, encuentras jpa-repository/usuario-persistencia/ como contexto autocontenido con sus entidades JPA, sus repositorios Spring Data, su implementación del gateway del dominio, sus mapeadores entre entidades JPA y entidades de dominio, todo junto porque conceptualmente pertenece junto.
La estructura de módulos técnicos permanece intacta. El dominio sigue siendo independiente. Los adaptadores siguen implementando contratos del dominio. Los entry points siguen invocando casos de uso. Clean Architecture se mantiene en todo su esplendor. Pero dentro de cada módulo, la organización refleja el negocio, no solo la técnica.
Los Beneficios Tangibles que Cambian Todo
Esta dualidad—módulos técnicos afuera, contextos de negocio adentro—transforma radicalmente la experiencia de desarrollo.
Cuando necesitas modificar el registro de usuarios seis meses después de implementarlo, abres domain/usecase/registrar-usuario/ y todo está ahí. No hay búsquedas en carpetas compartidas. No hay intentos de recordar dónde quedó el validador o el mapper. La lógica del caso de uso, sus DTOs, sus validadores, sus enriquecedores, sus utilidades—todo en un solo lugar. Abres api-rest/registrar-usuario-api/ y encuentras todo lo relacionado con cómo esa funcionalidad se expone vía REST. Abres jpa-repository/usuario-persistencia/ y encuentras todo lo relacionado con cómo se persiste.
La velocidad de comprensión se dispara. Un desarrollador nuevo asignado a modificar una funcionalidad específica puede abrir su contexto y ver inmediatamente qué hace, cómo lo hace, y qué elementos utiliza. No necesita entender todo el sistema, solo el contexto específico con el que trabajará. El onboarding que solía tomar semanas ahora toma días porque el conocimiento no está disperso por todo el código base sino contenido en unidades comprensibles.
El mantenimiento se simplifica dramáticamente. Un bug en el procesamiento de pedidos significa ir a domain/usecase/procesar-pedido/. La mayoría de las veces, el problema y la solución están completamente contenidos en ese contexto. Haces el cambio, ejecutas los tests de ese contexto específico, y tienes alta confianza de que no rompiste nada más porque la independencia entre contextos minimiza los efectos colaterales.
La evolución del sistema se vuelve orgánica y natural. Una funcionalidad crítica del negocio crece en complejidad: agregas más validadores en su carpeta validator/, más enriquecedores en su carpeta enricher/, más utilidades en su carpeta util/. Otra funcionalidad permanece simple porque así lo requiere el negocio, con solo el caso de uso, un par de DTOs, y un mapper básico. No hay presión por mantener todo al mismo nivel de complejidad o estructura uniforme. Cada contexto crece según sus propias necesidades.
El trabajo en equipo fluye mejor sin fricción constante. Múltiples desarrolladores trabajan simultáneamente en diferentes contextos—uno en registrar usuarios, otro en procesar pedidos, un tercero en consultar inventario—sin colisionar porque el código está físicamente separado. Los conflictos de merge que solían ser diarios ahora son raros. Las revisiones de código son más efectivas porque los cambios están claramente contenidos: puedes ver exactamente qué se modificó dentro de un contexto específico y entender su alcance sin necesitar conocimiento exhaustivo de todo el sistema.
Y quizás lo más valioso: la confianza al hacer cambios. Cuando todo lo relacionado con una funcionalidad está junto y los contextos son genuinamente independientes, puedes modificar código con la confianza de que tus cambios no tendrán efectos colaterales sorpresa en funcionalidades no relacionadas. Los tests del contexto verifican que no rompiste esa funcionalidad específica, y la independencia entre contextos garantiza que no afectaste otras inadvertidamente.
El Principio de Duplicación Intencional
Pero hay un elefante en la habitación que necesitamos abordar directamente: verás código aparentemente duplicado. Y eso va a incomodarte.
Dos contextos tendrán validadores que lucen similares. Tres contextos tendrán mappers que parecen hacer traducciones parecidas. Varios contextos tendrán utilidades que se ven redundantes. Tu instinto—entrenado por años de escuchar “Don’t Repeat Yourself”—gritará que esto está mal, que debes extraer, generalizar, compartir.
Necesitas resistir ese impulso porque está basado en una falsa equivalencia entre similitud y identidad.
Dos validadores que hoy lucen idénticos no son el mismo concepto. Uno valida emails en el contexto de registrar usuarios, donde quizás solo verificas el formato básico. Otro valida emails en el contexto de enviar campañas de marketing, donde quizás verificas que el dominio no esté en una lista de bloqueo, que el usuario haya dado consentimiento, que el email haya sido verificado previamente. Parecen el mismo código hoy, pero representan reglas de negocio de contextos diferentes que inevitablemente divergirán mañana.
Si hubieras compartido ese validador “para no duplicar código”, cuando uno de los contextos necesite evolucionar—y lo necesitará—enfrentarás una decisión imposible. O modificas el validador compartido y arriesgas romper todos los contextos que lo usan, o agregas condicionales que verifican desde qué contexto se está llamando (acoplamiento horrible), o terminas duplicando el código de todas formas cuando la presión del deadline no te deja tiempo para refactorizaciones elegantes.
La duplicación intencional es el precio que pagas por la independencia. Y resulta ser un precio extraordinariamente bajo comparado con el costo del acoplamiento que crearías compartiendo componentes prematuramente.
Esto no significa nunca compartir nada. Significa compartir solo lo que tiene una razón de negocio genuina para ser compartido. Un modelo de dominio como Usuario que representa el mismo concepto fundamental a través de múltiples contextos merece vivir en domain/model/usuario/ como elemento transversal. Un servicio de dominio con lógica compleja de cálculo de precios que múltiples casos de uso invocan justifica su existencia en domain/service/calculo-precios/. Pero un validador que casualmente verifica el mismo formato en dos contextos diferentes no necesita ser compartido solo porque el código se ve similar.
La guía es simple: extrae como transversal solo cuando hay identidad conceptual de negocio, no cuando hay mera similitud técnica superficial. Y cuando dudes, prefiere duplicar. Es más fácil extraer código duplicado después cuando verdaderamente lo necesitas que desenredar dependencias compartidas cuando los contextos necesitan divergir.
Cómo Convive con las Herramientas de Scaffolding
La pregunta práctica que surge inmediatamente es: si Scaffolding of Clean Architecture genera código en ubicaciones genéricas basadas en naturaleza técnica, ¿cómo logras esta organización por contextos?
La respuesta es un flujo de trabajo disciplinado que combina generación automática con reorganización consciente.
Cuando necesitas crear un caso de uso, ejecutas el comando de scaffolding que lo genera en domain/usecase/ en una estructura base genérica. Inmediatamente después, antes de escribir una línea de lógica, creas manualmente la carpeta de contexto domain/usecase/nombre-funcionalidad/ y mueves el archivo generado ahí. Creas las subcarpetas que ese caso de uso específico necesitará: dto/, mapper/, validator/, etc.
Cuando generas un entry point REST, el scaffolding lo crea en infrastructure/entry-points/api-rest/ en ubicación genérica. De inmediato creas la carpeta de contexto api-rest/nombre-funcionalidad-api/ y reorganizas. Cuando generas un adaptador de persistencia, se crea en infrastructure/driven-adapters/jpa-repository/ genéricamente. Creas jpa-repository/contexto-persistencia/ y contextualizas.
El scaffolding proporciona el esqueleto técnico correcto en el módulo correcto con la estructura base apropiada. Tú proporcionas la organización conceptual que refleja el negocio. Es trabajo adicional, sí, pero es trabajo que pagas una vez y recuperas mil veces cada vez que necesitas encontrar, entender, o modificar código.
Esta reorganización no puede ser opcional ni algo que “haremos cuando tengamos tiempo”. Debe ser parte no negociable del proceso de desarrollo desde el día uno. Cada componente generado se contextualiza inmediatamente antes de comenzar a escribir su lógica. Las revisiones de código verifican no solo que el código funciona sino que está correctamente organizado en su contexto apropiado.
La disciplina es crucial porque es fácil tomar atajos bajo presión. “Solo por esta vez dejaré el código donde el scaffolding lo generó, no tengo tiempo de reorganizar ahora.” Pero esos atajos se acumulan. La estructura se vuelve inconsistente—algunos componentes contextualizados, otros dispersos genéricamente—y gradualmente pierdes todos los beneficios. Es como mantener limpia una cocina: si lavas los platos después de cada comida es fácil, si los dejas acumular se vuelve insoportable.
Maximizando los Beneficios: Desarrollo Outside-In
Con la estructura clara y el proceso de reorganización establecido, hay una práctica que potencia enormemente los beneficios de esta organización por contextos: el desarrollo outside-in. No es obligatorio seguir este enfoque, pero resulta extraordinariamente efectivo para avanzar con la seguridad de que cada paso está correctamente implementado antes de pasar al siguiente. Esta afirmación se entiende mejor al contrastarla con los inconvenientes de la forma tradicional de iniciar el desarrollo. En la forma tradicional normalmente se comienza desde el dominio y se trabaja hacia afuera. Esto implica que no puedes validar realmente que algo funciona hasta que todas las capas están implementadas. Pasas días o semanas escribiendo código sin poder ejecutar nada end-to-end, descubriendo problemas de integración solo al final cuando son más caros de resolver. El enfoque que mejor aprovecha esta estructura es el opuesto: comenzar desde el punto de entrada y avanzar hacia adentro, validando cada capa inmediatamente después de crearla.
Empiezas con el entry point. Si la funcionalidad se expondrá vía REST, generas el controlador con scaffolding, lo reorganizas en su contexto api-rest/crear-pedido-api/, creas sus DTOs de request y response, y haces que devuelva datos inventados pero con la estructura correcta. Levantas la aplicación. Haces una petición HTTP real. El endpoint responde en menos de treinta minutos desde que comenzaste. Son datos falsos, pero el contrato de la API está validado y tienes algo tangible que puedes mostrar.
Ahora creas el caso de uso. Generas con scaffolding, reorganizas en domain/usecase/crear-pedido/, creas sus DTOs—diferentes de los de la API—y lo haces devolver también datos simulados. Creas los mapeadores en api-rest/crear-pedido-api/mapper/ que traducen entre DTOs de API y DTOs de caso de uso. Inyectas el caso de uso en el controlador y conectas el flujo.
Levantas la aplicación nuevamente. Haces una petición. Los datos fluyen: API recibe → mapea a lenguaje de dominio → caso de uso procesa → mapea a lenguaje de API → responde. Todo funciona. Siguen siendo datos simulados, pero la arquitectura de comunicación entre capas está validada. Has probado que las abstracciones encajan correctamente.
Continúas capa por capa. Si el caso de uso necesita un modelo transversal que no existe, lo creas en domain/model/pedido/ con su gateway. Si necesita lógica reutilizable, creas el servicio en domain/service/calculo-descuentos/. Cada uno inicialmente con lógica simplificada o simulada.
Implementas el adaptador de persistencia. Generas con scaffolding, organizas en jpa-repository/pedido-persistencia/ con sus entidades JPA, repositorios, implementación del gateway, mapeadores. Lo pruebas de forma aislada con tests de integración contra base de datos de prueba. Solo cuando funciona correctamente lo conectas al caso de uso. Haces una petición end-to-end y por primera vez los datos realmente se persisten y recuperan.
Agregas validadores al caso de uso, uno a la vez, en domain/usecase/crear-pedido/validator/. Pruebas que rechazan correctamente datos inválidos. Agregas enriquecedores en enricher/ que complementan información. Implementas clientes para servicios externos, cada uno en su contexto en rest-consumer/servicio-inventario/. En cada paso tienes algo funcional que puedes probar.
Este flujo outside-in con retroalimentación temprana transforma el desarrollo. Nunca estás más de un paso alejado de algo que funciona. Los problemas de integración se descubren tempranamente cuando son fáciles de resolver. Siempre tienes una versión funcional—aunque incompleta—en lugar de un sistema completo que no funciona hasta el final. Y la presión psicológica desaparece porque constantemente ves progreso tangible.
Con la estructura clara y el proceso de reorganización establecido, hay una práctica que potencia enormemente los beneficios de esta organización por contextos: el desarrollo outside-in. No es obligatorio seguir este enfoque, pero resulta extraordinariamente efectivo para avanzar con la seguridad de que cada paso está correctamente implementado antes de pasar al siguiente. Esta afirmación se entiende mejor al contrastarla con los inconvenientes de la forma tradicional de iniciar el desarrollo. En la forma tradicional normalmente se comienza desde el dominio y se trabaja hacia afuera. Esto implica que no puedes validar realmente que algo funciona hasta que todas las capas están implementadas. Pasas días o semanas escribiendo código sin poder ejecutar nada end-to-end, descubriendo problemas de integración solo al final cuando son más caros de resolver. El enfoque que mejor aprovecha esta estructura es el opuesto: comenzar desde el punto de entrada y avanzar hacia adentro, validando cada capa inmediatamente después de crearla.
Con la estructura clara y el proceso de reorganización establecido, hay una práctica que potencia enormemente los beneficios de esta organización por contextos: el desarrollo outside-in. No es obligatorio seguir este enfoque, pero resulta extraordinariamente efectivo para avanzar con la seguridad de que cada paso está correctamente implementado antes de pasar al siguiente. Esta afirmación se entiende mejor al contrastarla con los inconvenientes de la forma tradicional de iniciar el desarrollo. En la forma tradicional normalmente se comienza desde el dominio y se trabaja hacia afuera. Esto implica que no puedes validar realmente que algo funciona hasta que todas las capas están implementadas. Pasas días o semanas escribiendo código sin poder ejecutar nada end-to-end, descubriendo problemas de integración solo al final cuando son más caros de resolver. El enfoque que mejor aprovecha esta estructura es el opuesto: comenzar desde el punto de entrada y avanzar hacia adentro, validando cada capa inmediatamente después de crearla.
Las Incomodidades Reales
Seamos honestos sobre los desafíos porque existen y necesitas conocerlos antes de adoptar esta aproximación. La disciplina de reorganización después de cada generación de scaffolding es real y constante. Bajo presión de deadlines, saltarse este paso es tentador. “Lo reorganizaré después” se convierte en “nunca”. La solución no es intentar automatizar la reorganización—requiere juicio humano sobre qué constituye un contexto apropiado—sino hacer de la reorganización una parte no negociable del proceso. La definición de “done” incluye código correctamente contextualizado. Las revisiones de código lo verifican. Los desarrolladores nuevos son entrenados en esto desde el día uno. Las estructuras de carpetas serán más profundas. Más niveles de anidamiento que en estructuras tradicionales. Inicialmente esto se siente lento y confuso. Los IDEs modernos ayudan significativamente con búsquedas rápidas y navegación inteligente, pero aún así hay un período de adaptación de algunas semanas. Después, la mayoría de desarrolladores encuentra que localizar código es más rápido porque saben exactamente dónde buscar: todo lo relacionado con una funcionalidad está en su contexto. Decidir qué extraer como transversal y qué mantener en contextos requiere experiencia y juicio. No hay reglas absolutas que puedas seguir mecánicamente. Un modelo de dominio usado extensamente claramente debe ser transversal. Un servicio con lógica compleja reutilizable justifica extracción. Pero un mapper usado por un solo caso de uso debe permanecer en ese contexto. Esta decisión requiere práctica, y a veces te equivocarás y necesitarás refactorizar. Eso es normal y esperado. El tamaño del código base crecerá más que en aproximaciones tradicionales debido a la duplicación intencional. Esto puede parecer problemático especialmente en equipos acostumbrados a optimizar por menos líneas de código. Pero la métrica relevante no es el tamaño absoluto sino la mantenibilidad y comprensibilidad. Un código base más grande pero bien organizado, donde cada pieza tiene su lugar claro, es infinitamente más fácil de mantener que un código base más pequeño con componentes compartidos complejos y dependencias cruzadas que hacen imposible entender el impacto de los cambios.
Haciendo la Transición en Tu Equipo
Si esto resuena contigo y quieres adoptarlo, la transición requiere más que cambiar la estructura de carpetas. Comienza solo con código nuevo. Intentar refactorizar todo un código base existente de una vez es una receta para el fracasgo: demasiado costo, demasiado riesgo, demasiada resistencia del equipo. Aplica la filosofía a nuevas funcionalidades que implementes desde cero. Refactoriza código existente solo cuando ese código necesita modificaciones significativas de todas formas—entonces aprovechar para reorganizarlo en contextos apropiados es inversión que ya estás haciendo. Esta adopción gradual permite que el equipo aprenda sin el trauma de una reescritura masiva. Por algunos meses convivirán dos estilos: código viejo en estructura tradicional, código nuevo en contextos. Está bien. Eventualmente, a medida que el código viejo se modifica, se va reorganizando. En un año, la mayoría del código activo estará contextualizado. Invierte en documentación viva con ejemplos concretos de tu código base real. Abstracciones teóricas sobre “contextos autocontenidos” no funcionan tan bien como mostrar “mira, así organizamos el caso de uso de procesar pedidos, aquí están todos sus elementos, esta es la razón por la que cada uno está donde está”. Cuando los desarrolladores pueden ver ejemplos reales del propio proyecto, la comprensión es inmediata. Las sesiones de pair programming donde desarrolladores experimentados en la filosofía trabajan con nuevos miembros aplicándola en práctica valen más que cualquier documento. Ver cómo alguien genera código con scaffolding y luego inmediatamente lo reorganiza, cómo decide qué subcarpetas crear, cómo identifica qué debe ser transversal versus específico del contexto—eso se aprende haciendo, no leyendo. Las revisiones de código son críticas para mantener integridad arquitectónica. Verifica que el código está en el contexto correcto, que sigue principios de autocontención, que no está creando acoplamiento innecesario. Esta verificación debe tener el mismo peso que verificar corrección funcional. Si el código funciona pero está mal organizado, solicitar cambios no es pedantería—es proteger la mantenibilidad a largo plazo del sistema. Y mantén flexibilidad dentro del marco. No todo contexto necesita la misma estructura. Un caso de uso simple no necesita todas las subcarpetas que uno complejo requiere. Lo importante son los principios—autocontención, cohesión conceptual, independencia—no seguir rígidamente una plantilla.
Performance: La Pregunta que Todos Hacen
Eventualmente alguien preguntará: “¿Toda esta separación y múltiples traducciones entre DTOs no tiene costo de performance prohibitivo?” La respuesta pragmática: en la vasta mayoría de aplicaciones empresariales, no. El costo de mapear entre DTOs de API, DTOs de caso de uso, entidades de dominio, y entidades JPA se mide en microsegundos. Las operaciones que realmente importan—queries a base de datos, llamadas HTTP a servicios externos, procesamiento de lógica de negocio compleja—se miden en milisegundos o más. Los mapeos son ruido estadístico en comparación. Cuando la performance es genuinamente crítica—procesamiento batch de millones de registros, sistemas de alta frecuencia, servicios con SLAs de latencia extremos—la arquitectura no lo prohíbe. Un caso de uso puede saltarse algunos mapeos, trabajando más directamente con representaciones de niveles inferiores si es necesario. La clave es que esto sea una decisión consciente, documentada, y justificada por mediciones reales de performance bajo carga real, no por optimización prematura basada en suposiciones. Las optimizaciones del compilador Java y la JVM también ayudan enormemente. El inlining de métodos pequeños significa que muchos mapeos que parecen caros en el código fuente son esencialmente gratuitos en el bytecode optimizado. La eliminación de código muerto elimina paths que nunca se ejecutan. El profile-guided optimization del JIT compiler optimiza los caminos que realmente se usan frecuentemente. La guía es clara: construye con la arquitectura limpia por defecto. Mide cuando tengas dudas reales. Optimiza solo donde las mediciones bajo carga real muestren necesidad. La claridad arquitectónica facilita la optimización cuando es necesaria porque es trivial identificar dónde está el cuello de botella—está en un contexto específico—y modificar solo esa parte sin afectar el resto.
El Impacto en la Cultura del Equipo
Más allá de la estructura de carpetas, esta filosofía cambia cómo los equipos trabajan y colaboran. El ownership del código se vuelve natural y claro. Cuando todo lo relacionado con una funcionalidad está en un contexto específico, es fácil asignar ownership de ese contexto a alguien. No significa que solo esa persona puede tocarlo—eso crearía silos de conocimiento—pero hay alguien responsable de su calidad, coherencia, y evolución. Cuando surge una pregunta sobre esa funcionalidad, hay un punto de contacto claro. Cuando necesita evolucionar, hay alguien que entiende su contexto completo. La planificación de sprints se simplifica porque las historias de usuario frecuentemente se mapean directamente a casos de uso, y los casos de uso son contextos autocontenidos. Estimar el esfuerzo se vuelve más predecible: implementar un caso de uso significa crear su contexto con los elementos que necesita. La variabilidad viene de cuántos y qué tipo de elementos específicos requiere—validadores complejos versus simples, múltiples enriquecedores versus ninguno—pero el patrón general es consistente. Las estimaciones mejoran porque hay menos incertidumbre sobre alcance y dependencias. La colaboración cambia de naturaleza. En lugar de conflictos constantes por múltiples personas modificando los mismos archivos compartidos, diferentes desarrolladores trabajan en diferentes contextos con mínima interferencia. Cuando necesitan coordinación, típicamente es a través de interfaces bien definidas—un caso de uso invocando un servicio de dominio, un entry point usando un caso de uso—no modificando los mismos archivos internos simultáneamente. El testing se vuelve más natural. Cada contexto puede probarse de forma aislada con sus dependencias mockeadas apropiadamente. Los tests unitarios se enfocan en lógica específica del contexto. Los tests de integración verifican que el contexto se comunica correctamente con sus dependencias reales. Los tests end-to-end verifican que el flujo completo funciona atravesando múltiples contextos. Esta separación hace que los tests sean más simples de escribir, más rápidos de ejecutar, y más fáciles de mantener porque el alcance de cada nivel de testing es claro. La rotación de personas—tanto salidas como nuevas incorporaciones—se maneja mejor. El conocimiento no está uniformemente distribuido por un código base monolítico donde entender cualquier parte requiere entender el todo. El conocimiento está organizado por contextos. Un desarrollador saliente puede documentar y traspasar los contextos de los que tenía ownership específico. Un desarrollador entrante puede comenzar tomando ownership de contextos particulares, aprendiendo el sistema incrementalmente en lugar de necesitar una descarga masiva de conocimiento de todo desde el día uno.
Evolución y Futuro
Esta filosofía híbrida no es un destino final sino un punto en la evolución continua de cómo organizamos código complejo. Las herramientas seguirán mejorando. Los IDEs se volverán más inteligentes en entender y navegar estructuras modulares complejas. Las herramientas de scaffolding podrían eventualmente aprender a generar código ya organizado por contextos, preguntando al desarrollador a qué contexto de negocio pertenece el componente antes de generarlo. La generación de código asistida por IA podría entender patrones arquitectónicos como esta filosofía de contextos y generar código que automáticamente se organiza correctamente, reduciendo la carga de disciplina manual. Las herramientas de análisis estático podrían detectar violaciones de la organización por contextos, identificando cuando un contexto accede directamente a detalles internos de otro o cuando la estructura se está volviendo inconsistente. A medida que más sistemas evolucionan hacia arquitecturas distribuidas, la clara separación de contextos se vuelve aún más valiosa. Los bounded contexts bien definidos facilitan decisiones sobre qué debe desplegarse junto y qué podría beneficiarse de despliegue independiente como microservicios. Los módulos Gradle proporcionan las fronteras naturales para estas decisiones, y la organización por contextos asegura que cada unidad desplegable sea cohesiva y completa. Pero más allá de las herramientas futuras, los principios permanecen: autocontención facilita comprensión, cohesión conceptual facilita mantenimiento, independencia entre contextos facilita evolución. Estos principios son atemporales incluso si los detalles de implementación evolucionan con nuevas tecnologías.
Casos Reales y Lecciones Aprendidas
En equipos que han adoptado esta aproximación, ciertos patrones emergen consistentemente. La transición inicial típicamente toma entre cuatro y ocho semanas. Las primeras dos semanas son de confusión y resistencia—“esto parece más complicado”, “por qué estamos duplicando código”, “no entiendo dónde poner las cosas”. Las siguientes dos a cuatro semanas son de adaptación—el músculo de reorganizar después de scaffolding se desarrolla, las decisiones sobre qué contextualizar versus qué extraer se vuelven más naturales. Después de seis a ocho semanas, la mayoría de desarrolladores reporta que encontrar y modificar código se siente significativamente más fácil que antes. El momento “ajá” típicamente llega cuando un desarrollador necesita modificar una funcionalidad que implementó semanas antes. Abre el contexto esperando tener que buscar piezas dispersas por todo el proyecto, y descubre sorprendido que todo está ahí. “Oh, esto realmente funciona.” Los equipos exitosos típicamente desarrollan sus propias convenciones específicas sobre nombrado de contextos, cuándo crear subcarpetas adicionales, cómo documentar decisiones de diseño dentro de contextos. Estas convenciones locales complementan los principios generales, adaptando la filosofía a las necesidades específicas del dominio y la cultura del equipo. Un error común es intentar que todos los contextos tengan exactamente la misma estructura. Un caso de uso complejo puede tener ocho subcarpetas diferentes. Uno simple puede tener solo tres. Ambos están bien. La estructura sirve a la funcionalidad, no al revés. Forzar uniformidad rígida crea carpetas vacías o artificialmente pobladas que no agregan valor. Otro error es ser demasiado conservador con la duplicación, intentando extraer cualquier similitud mínima. Esto recrea el problema original de componentes compartidos con dependencias complejas. La guía que funciona: cuando dudes si extraer, espera. Duplica inicialmente. Solo extrae cuando el tercer o cuarto contexto necesita exactamente lo mismo y tienes evidencia clara de que representa un concepto verdaderamente transversal del negocio, no solo similitud técnica superficial.
Relación con Otros Patrones
Esta filosofía no existe en vacío sino que complementa y se integra con otros patrones y prácticas establecidas. Domain-Driven Design proporciona el vocabulario para identificar y organizar contextos. Los bounded contexts de DDD se mapean naturalmente a agrupaciones de contextos en esta arquitectura. Las entidades, value objects, aggregates, y domain events de DDD encuentran su lugar en los contextos de modelo. Los servicios de dominio de DDD corresponden directamente a los servicios de dominio en esta estructura. CQRS puede aplicarse dentro de la organización por contextos. Los casos de uso que modifican estado (comandos) pueden organizarse claramente separados de los que solo leen (queries), permitiendo optimizaciones diferentes para cada tipo sin sacrificar claridad organizacional. Event Sourcing se integra naturalmente. Los domain events que las entidades generan pueden persistirse como event stream. Los adaptadores de persistencia implementan event stores. Los casos de uso publican eventos que otros contextos consumen, manteniendo independencia entre bounded contexts mientras permiten coordinación. La relación con Microservicios es interesante. Cada bounded context con sus casos de uso, servicios, y adaptadores podría potencialmente extraerse como microservicio independiente. Los módulos Gradle proporcionan fronteras naturales para esta extracción. Los gateways que actualmente se implementan con adaptadores locales podrían reemplazarse con adaptadores que hacen llamadas remotas. La organización por contextos facilita esta evolución porque las dependencias entre contextos son explícitas a través de gateways, haciendo visible el acoplamiento que necesitaría convertirse en comunicación remota.
El Verdadero Valor
Al final, todo esto se reduce a una verdad simple: la arquitectura de software existe para facilitar resolver problemas de negocio de manera efectiva y sostenible en el tiempo.
Una buena arquitectura es aquella que permite a los desarrolladores entender rápidamente qué hace el código, hacer cambios con confianza, y evolucionar el sistema según las necesidades del negocio cambian. No es la que se ve más elegante en un diagrama. No es la que usa las tecnologías más nuevas. No es la que tiene menos líneas de código. Es la que funciona para el equipo que la mantiene y el negocio que la necesita.
Esta filosofía híbrida de contextos dentro de módulos técnicos busca precisamente eso. No promete eliminar toda complejidad—la complejidad es inherente a sistemas empresariales que resuelven problemas complejos—pero promete organizarla de manera que sea manejable y comprensible.
Promete que cuando necesites modificar algo, sabrás dónde buscar porque todo lo relacionado está junto. Promete que tus cambios estarán contenidos y sus efectos predecibles porque los contextos son independientes. Promete que nuevos desarrolladores pueden comenzar a contribuir sin necesitar entender todo el sistema porque pueden tomar ownership de contextos específicos.
No es la única manera de organizar código, y no será la mejor para todos los proyectos y equipos. Pero para equipos que trabajan con herramientas de scaffolding que generan estructura modular, que construyen aplicaciones empresariales complejas donde el código vive y evoluciona durante años, y que valoran tanto la disciplina arquitectónica como la productividad práctica, ofrece un balance probado entre estructura y pragmatismo.
La adopción requiere más que cambiar carpetas. Requiere cambiar cómo piensas sobre organización de código. Requiere disposición a cuestionar dogmas como “nunca duplicar código” y reconocer que la duplicación intencional es frecuentemente mejor que el acoplamiento prematuro. Requiere disciplina para mantener integridad arquitectónica incluso bajo presión. Requiere inversión en documentación, entrenamiento, y procesos de revisión que refuercen los principios.
Pero para equipos dispuestos a hacer esa inversión, los retornos son reales y duraderos. Código que seis meses después todavía puedes entender rápidamente. Cambios que implementas con confianza sabiendo que no romperás cosas no relacionadas. Sistemas que crecen en funcionalidad sin colapsar bajo su propio peso. En un mundo donde el software exitoso inevitablemente crece en complejidad, eso no es poca cosa.
Así que la próxima vez que abras un proyecto y necesites modificar cómo se procesa un pedido, no pasarás treinta minutos buscando piezas dispersas por toda la estructura. Abrirás domain/usecase/procesar-pedido/ y todo estará ahí. Esa es la promesa. Esa es la diferencia.




























