Observabilidad sin Ruido: Diseñando un Sistema de Logs con AOP en Arquitecturas DDD — Parte II
- Mauricio ECR
- Arquitectura
- 18 May, 2026
La primera parte de este artículo construyó el argumento conceptual: por qué los logs dispersos se convierten en deuda técnica, cómo AOP permite centralizar la observabilidad sin contaminar la lógica de negocio, qué información debe registrarse en cada capa de una arquitectura DDD, y cómo los campos estructurados convierten un archivo de texto en una fuente de inteligencia operacional. Lo que quedó pendiente fue la demostración concreta: cómo se construye ese sistema, qué decisiones se toman en cada pieza, y por qué cada una de ellas importa.
Eso es exactamente lo que ocupa esta segunda parte. El objetivo es preciso: que al terminar de leerla, un desarrollador con experiencia en Spring pueda reproducir el sistema completo en su proyecto. No como una lista de pasos a seguir ciegamente, sino con el entendimiento de por qué cada componente existe, qué problema resuelve y qué ocurriría si se omitiera o se implementara de otra manera.
El stack es Java 21, Spring Boot 3.5.x, Gradle. Las dependencias que habilitan el sistema son spring-boot-starter-aop, que trae AspectJ y el soporte de proxies de Spring, y jackson-datatype-jsr310, que permite serializar correctamente los tipos de fecha y hora de Java 8 en los logs. Lombok está presente por conveniencia, pero no es estructuralmente necesario. Ninguna dependencia adicional es requerida.
El proyecto de ejemplo
Para que cada decisión técnica tenga contexto real, el sistema de logs se implementa sobre un proyecto concreto: una API REST que registra usuarios. Es un caso de uso deliberadamente simple, lo suficiente para que el flujo sea fácil de seguir, pero con la estructura completa de una arquitectura DDD: entrada HTTP, caso de uso, validaciones de dominio, persistencia, y manejo de errores.
El proyecto tiene esta estructura:
src/main/java/com/app_247/blog/id202603212000art/
│
├── Id202603212000artApplication.java ★ [LOG]
│
├── applications/
│ └── aop/
│ ├── aspect/
│ │ └── MethodLoggingAspect.java ★ [LOG]
│ └── config/
│ ├── JacksonConfig.java ★ [LOG]
│ └── LoggingAopProperties.java ★ [LOG]
│
├── domain/
│ ├── model/
│ │ ├── exception/
│ │ │ ├── BusinessException.java
│ │ │ └── DomainValidationException.java
│ │ └── usuario/
│ │ ├── gateway/
│ │ │ └── IUsuarioGateway.java
│ │ └── Usuario.java
│ └── usecase/
│ └── registrarusuario/
│ ├── dto/
│ │ ├── RegistrarUsuarioIn.java
│ │ └── RegistrarUsuarioOut.java
│ ├── enricher/
│ │ └── UsernameEnricher.java
│ ├── validator/
│ │ ├── EdadValidator.java
│ │ ├── EmailDominioValidator.java
│ │ └── NombreValidator.java
│ └── RegistrarUsuarioUseCase.java
│
└── infrastructure/
├── drivenadapters/
│ └── jpa/
│ └── usuario/
│ ├── adapter/
│ │ └── UsuarioPersistenciaAdapter.java
│ ├── entity/
│ │ └── UsuarioEntity.java
│ ├── mapper/
│ │ └── UsuarioPersistenciaMapper.java
│ └── repository/
│ └── UsuarioJpaRepository.java
└── entrypoints/
└── api/
└── registrarusuario/
├── dto/
│ ├── RegistrarUsuarioRequest.java
│ └── RegistrarUsuarioResponse.java
├── mapper/
│ └── RegistrarUsuarioApiMapper.java
├── RegistrarUsuarioController.java
└── util/
└── Exception/
└── GlobalExceptionHandler.java
src/main/resources/
└── application.properties ★ [LOG]Las clases marcadas con ★ [LOG] son las que forman el sistema de observabilidad. Todo lo demás es la lógica del negocio y la infraestructura del proyecto, que no tiene ninguna instrucción de log y no necesita tenerla.
El flujo de una solicitud
Antes de abrir cualquier clase del sistema de logs vale la pena recorrer el flujo completo de una solicitud de registro de usuario. Es el flujo que el aspecto va a observar, y entenderlo con claridad hace que cada decisión de implementación tenga sentido inmediato.
El cliente envía un POST /api/v1/usuarios con un cuerpo JSON que contiene nombre, email y edad. A partir de ahí, la solicitud atraviesa estas capas en orden:
RegistrarUsuarioController es el punto de entrada. Recibe el request HTTP, lo valida con Bean Validation (@Valid), y usa RegistrarUsuarioApiMapper para convertir el RegistrarUsuarioRequest en un RegistrarUsuarioIn, que es el DTO que entiende el dominio. Luego invoca el caso de uso y convierte el resultado de vuelta a un RegistrarUsuarioResponse para la respuesta HTTP. El controlador no tiene lógica de negocio: solo traduce entre el mundo HTTP y el mundo del dominio.
RegistrarUsuarioUseCase es donde ocurre la orquestación. Recibe el RegistrarUsuarioIn y ejecuta la secuencia de negocio: primero llama a NombreValidator, EdadValidator y EmailDominioValidator para validar que los datos cumplan las reglas del dominio. Luego consulta el gateway para verificar que el email no esté ya registrado. Si todo es válido, usa UsernameEnricher para generar el nombre de usuario a partir del email, construye el objeto Usuario y lo persiste a través del gateway. Finalmente construye y retorna el RegistrarUsuarioOut.
Es importante notar que NombreValidator, EdadValidator, EmailDominioValidator y UsernameEnricher son clases con métodos estáticos, sin estado, sin anotaciones de Spring. El UseCase los llama directamente como utilidades. No son beans y el aspecto no los ve, lo cual es correcto: su comportamiento queda capturado por la observación del UseCase que los invoca.
IUsuarioGateway es la interfaz del puerto de salida. El dominio la define; la infraestructura la implementa. El UseCase solo conoce la interfaz, nunca la implementación concreta.
UsuarioPersistenciaAdapter es la implementación del gateway. Está anotado con @Component, es un bean de Spring, y es aquí donde realmente ocurre la interacción con la base de datos. Usa UsuarioPersistenciaMapper para convertir entre el modelo de dominio Usuario y la entidad JPA UsuarioEntity, y delega en UsuarioJpaRepository para las operaciones sobre H2.
GlobalExceptionHandler intercepta cualquier excepción que no haya sido manejada antes de llegar al cliente. Para DomainValidationException devuelve un 422 con el detalle del campo que falló. Para BusinessException devuelve un 409 con el código de error. Para errores de validación de Bean Validation devuelve un 400 con el mapa de campos y mensajes.
Con ese recorrido claro, el flujo completo se puede representar así:
POST /api/v1/usuarios
│
▼
RegistrarUsuarioController ← @RestController ★ interceptado
│ toCommand()
▼
RegistrarUsuarioApiMapper ← @Component (MapStruct)
│ RegistrarUsuarioIn
▼
RegistrarUsuarioUseCase ← @Service ★ interceptado
│
├── NombreValidator.validar() ← clase plana, NO interceptada
├── EdadValidator.validar() ← clase plana, NO interceptada
├── EmailDominioValidator.validar() ← clase plana, NO interceptada
│
├── gateway.existeEmail()
│ └── UsuarioPersistenciaAdapter#existeEmail ← @Component ★ interceptado
│ └── UsuarioJpaRepository (Spring Data)
│
├── UsernameEnricher.generarUsername() ← clase plana, NO interceptada
│
└── gateway.guardar()
└── UsuarioPersistenciaAdapter#guardar ← @Component ★ interceptado
└── UsuarioJpaRepository (Spring Data)
│
▼ RegistrarUsuarioOut
RegistrarUsuarioController
│ toResponse()
▼
RegistrarUsuarioApiMapper
│
▼
RegistrarUsuarioResponse → HTTP 201Este flujo es el que el aspecto va a observar en tiempo de ejecución. Cada clase marcada con ★ interceptado genera sus propios registros de INPUT, OUTPUT y TIMING sin que ninguna de ellas sepa que está siendo observada. Las clases planas que no son beans simplemente no aparecen en los logs, y eso es correcto: su comportamiento está implícito en la observación de las capas que las contienen.
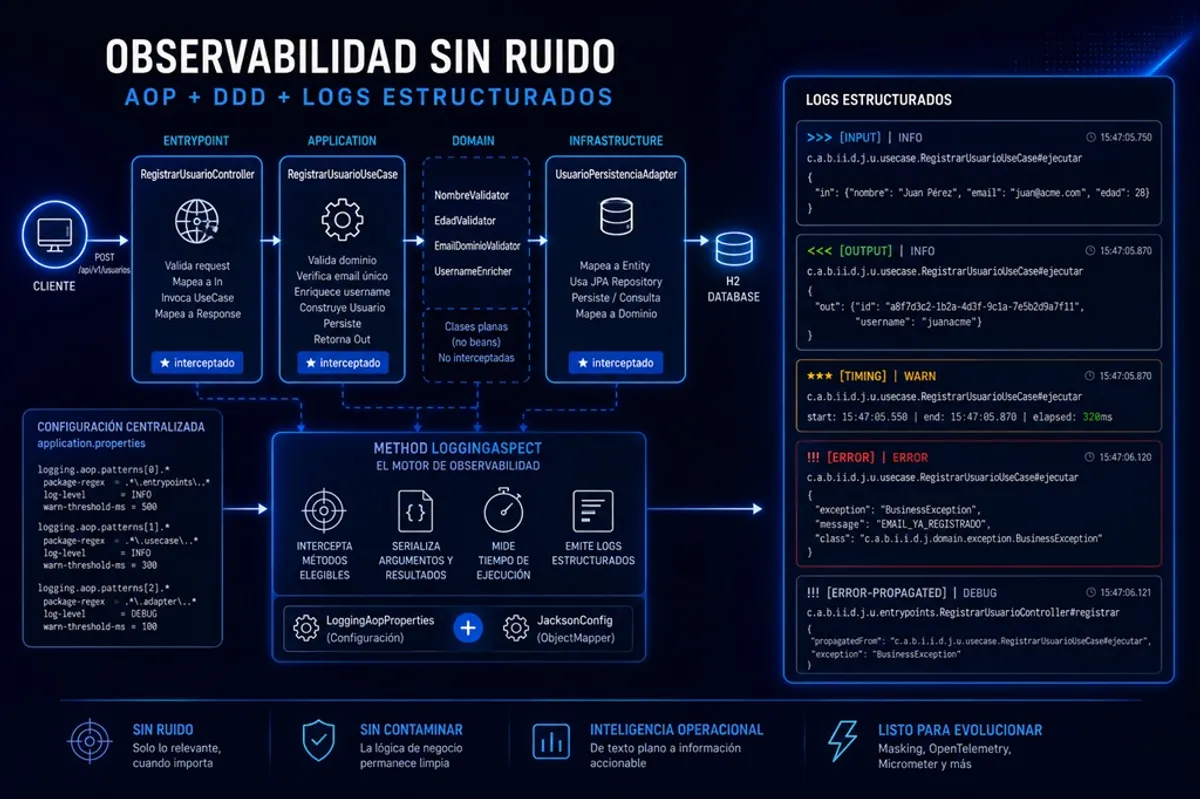
La arquitectura del sistema de logs
Con el flujo del proyecto claro, el sistema de logs se puede describir con precisión. Son tres piezas con responsabilidades distintas que operan juntas:
LoggingAopProperties es la configuración. Define qué interceptar: qué paquetes, qué clases, qué métodos, en qué nivel de log y a partir de qué tiempo de ejecución emitir una advertencia. No sabe nada del aspecto ni de Jackson.
MethodLoggingAspect es el motor. Intercepta cada método elegible, mide el tiempo, serializa los argumentos y resultados, y emite los registros según las reglas que encontró en las propiedades. No sabe nada de la lógica de negocio del proyecto.
JacksonConfig proporciona el ObjectMapper que el aspecto usa para convertir objetos Java en texto JSON. Está configurado para manejar correctamente los tipos de fecha de Java 8, que sin esta configuración se serializarían como arrays de números en lugar de strings ISO.
La relación entre las tres piezas es deliberadamente asimétrica: LoggingAopProperties no sabe nada del aspecto, y el aspecto no sabe nada de Jackson más allá de que tiene un ObjectMapper disponible. Cada pieza tiene una responsabilidad única y bien delimitada.
LoggingAopProperties: el contrato de configuración
Todo el comportamiento del sistema de logs se controla desde application.properties a través de LoggingAopProperties. Esta clase es un @ConfigurationProperties que mapea el prefijo logging.aop a una estructura de objetos en memoria:
@Data
@ConfigurationProperties(prefix = "logging.aop")
public class LoggingAopProperties {
private boolean enabled = true;
private String basePackage = "com.app_247.blog.id202603212000art";
private List<PatternConfig> patterns = List.of();
@Data
public static class PatternConfig {
private String packageRegex = ".*";
private String classRegex = ".*";
private String methodRegex = ".*";
private String logLevel = "INFO";
private long warnThresholdMs = 500L;
}
}La estructura interna PatternConfig representa una regla de interceptación. Tiene tres expresiones regulares que se evalúan contra el paquete, el nombre simple de la clase y el nombre del método. Si las tres hacen match, la regla aplica y sus otros dos campos determinan el comportamiento: logLevel controla en qué nivel se emiten los registros normales de esa capa, y warnThresholdMs define el umbral de tiempo a partir del cual el registro de timing se eleva automáticamente a WARN independientemente del nivel configurado.
Los valores por defecto de las tres regex son ".*", que en regex significa “cualquier cosa”. Esto garantiza que una PatternConfig construida sin configuración explícita intercepta todo, lo cual es un default seguro para desarrollo pero que en producción se reemplaza por reglas precisas.
Para que Spring Boot cargue esta clase al arrancar, la clase principal de la aplicación debe registrarla explícitamente:
@SpringBootApplication
@EnableConfigurationProperties(LoggingAopProperties.class)
public class Id202603212000artApplication {
public static void main(String[] args) {
SpringApplication.run(Id202603212000artApplication.class, args);
}
}@EnableConfigurationProperties es el mecanismo que le indica a Spring Boot que debe crear un bean de tipo LoggingAopProperties y enlazarlo con el prefijo logging.aop del archivo de propiedades. Sin esta anotación, la clase existe pero nunca se puebla: el aspecto recibiría una instancia con todos los valores por defecto y sin ningún patrón configurado, lo que significa que no interceptaría nada. Es un error silencioso difícil de diagnosticar si no se conoce el mecanismo.
La configuración del proyecto de ejemplo define tres patrones, uno por cada capa que se quiere observar:
logging.aop.enabled=true
logging.aop.base-package=com.app_247.blog.id202603212000art
# UseCase
logging.aop.patterns[0].package-regex=com\\.app_247\\.blog\\.id202603212000art\\.domain\\.usecase.*
logging.aop.patterns[0].class-regex=.*UseCase
logging.aop.patterns[0].method-regex=.*
logging.aop.patterns[0].log-level=INFO
logging.aop.patterns[0].warn-threshold-ms=300
# Adapter de persistencia
logging.aop.patterns[1].package-regex=com\\.app_247\\.blog\\.id202603212000art\\.infrastructure\\.drivenadapters.*
logging.aop.patterns[1].class-regex=.*Adapter
logging.aop.patterns[1].method-regex=.*
logging.aop.patterns[1].log-level=DEBUG
logging.aop.patterns[1].warn-threshold-ms=100
# Controller
logging.aop.patterns[2].package-regex=com\\.app_247\\.blog\\.id202603212000art\\.infrastructure\\.entrypoints.*
logging.aop.patterns[2].class-regex=.*Controller
logging.aop.patterns[2].method-regex=.*
logging.aop.patterns[2].log-level=INFO
logging.aop.patterns[2].warn-threshold-ms=500Tres decisiones de diseño visibles en esta configuración merecen atención. Primera: el adapter de persistencia tiene log-level=DEBUG mientras que el UseCase y el Controller tienen log-level=INFO. Esto significa que en producción con nivel INFO configurado, los logs del adapter son invisibles por defecto y solo aparecen cuando se activa DEBUG dinámicamente para diagnosticar un problema. La lógica es que saber que el UseCase llamó al adapter y cuánto tardó ya es información suficiente en condiciones normales; el detalle de qué exactamente se guardó o consultó es información de diagnóstico que solo se necesita ocasionalmente.
Segunda: el umbral de WARN del adapter es de 100ms, mucho más estricto que los 300ms del UseCase y los 500ms del Controller. Esto refleja una expectativa operacional: una operación de base de datos que tarde más de 100ms en este proyecto es una señal de alerta, mientras que el UseCase puede acumular ese tiempo y más en su orquestación sin que sea necesariamente un problema.
Tercera: los patrones se evalúan en orden y se aplica el primero que haga match. Si en el futuro existiera una clase que fuera a la vez un UseCase y un Adapter, lo cual no debería ocurrir en una arquitectura DDD bien diseñada pero podría ocurrir en un proyecto en transición, el patrón 0 ganaría porque aparece primero. Esta semántica de primer match es predecible y fácil de razonar.
JacksonConfig: el ObjectMapper para los logs
El aspecto necesita convertir los argumentos y resultados de los métodos en texto para escribirlos en el log. Jackson es la herramienta natural para esto en un proyecto Spring, pero la configuración por defecto tiene un problema concreto con los tipos de fecha de Java 8.
Sin configuración adicional, un LocalDateTime como 2026-05-18T15:47:05.875 se serializa como un array de números: [2026,5,18,15,47,5,875000000]. En un log de producción eso es ilegible. La solución es registrar el módulo JavaTimeModule y deshabilitar la serialización de fechas como timestamps:
@Configuration
public class JacksonConfig {
@Bean
public ObjectMapper objectMapper() {
ObjectMapper mapper = new ObjectMapper();
mapper.registerModule(new JavaTimeModule());
mapper.disable(SerializationFeature.WRITE_DATES_AS_TIMESTAMPS);
return mapper;
}
}El resultado es que LocalDateTime aparece en los logs como "2026-05-18T15:47:05.8756894", que es exactamente lo que se ve en la salida de consola de referencia.
Una pregunta legítima es por qué esta configuración vive en el paquete applications/aop/config y no en un paquete de configuración general de la aplicación. La respuesta es de propiedad: este ObjectMapper existe para el sistema de logs, no para la aplicación en general. En el futuro, cuando se incorpore el sistema de enmascaramiento que se documentará en la tercera parte de esta serie, este mapper recibirá configuración adicional específica para logs que no debe afectar a las respuestas HTTP. Mantenerlo en el paquete del sistema de logs hace explícita esa propiedad desde el principio.
MethodLoggingAspect: el motor de la interceptación
Con la configuración clara y el ObjectMapper disponible, el aspecto puede construirse. MethodLoggingAspect es un @Component anotado con @Aspect que recibe por inyección las propiedades y el mapper:
@Slf4j
@Aspect
@Component
@RequiredArgsConstructor
@ConditionalOnProperty(prefix = "logging.aop", name = "enabled", havingValue = "true", matchIfMissing = true)
public class MethodLoggingAspect {
private final ObjectMapper objectMapper;
private final LoggingAopProperties properties;
private final ConcurrentHashMap<String, Optional<PatternConfig>> matchCache = new ConcurrentHashMap<>();@ConditionalOnProperty con matchIfMissing = true significa que el aspecto está activo por defecto aunque la propiedad logging.aop.enabled no aparezca en el archivo de configuración. Solo se desactiva si la propiedad está explícitamente en false. Esto es un default sensato: en un proyecto nuevo donde todavía no se ha configurado nada, el sistema de logs funciona.
El matchCache es un ConcurrentHashMap de instancia, no estático. Esto es deliberado: si en algún escenario de pruebas o de recarga de contexto se creara una nueva instancia del aspecto, el cache empieza vacío y se reconstituye limpiamente. Un cache estático compartiría estado entre instancias del aspecto, lo que en tests de integración puede producir comportamientos inesperados difíciles de reproducir.
El pointcut y el filtro inicial
El pointcut captura todos los beans anotados con los estereotipos principales de Spring, excluyendo el propio paquete del aspecto:
@Around("(within(@org.springframework.stereotype.Service *) " +
"|| within(@org.springframework.stereotype.Component *) " +
"|| within(@org.springframework.web.bind.annotation.RestController *)" +
"|| within(@org.springframework.stereotype.Repository *)) " +
"&& !within(com.app_247.blog.id202603212000art.aop..*)")
public Object logMethod(ProceedingJoinPoint joinPoint) throws Throwable {Usar within con estereotipos en lugar de una expresión de paquete tiene una implicación directa en DDD que ya se mencionó al describir el flujo: los validadores y enrichers del dominio, que son clases planas sin anotaciones de Spring, no son interceptados. El aspecto solo ve lo que Spring gestiona, y eso es exactamente lo correcto.
Lo primero que hace el advice una vez que captura una invocación es extraer la información del método y aplicar el filtro de paquete base:
MethodSignature signature = (MethodSignature) joinPoint.getSignature();
Method method = signature.getMethod();
String packageName = method.getDeclaringClass().getPackageName();
String className = method.getDeclaringClass().getSimpleName();
String methodName = method.getName();
if (!packageName.startsWith(properties.getBasePackage())) {
return joinPoint.proceed();
}Este filtro descarta en una comparación de strings todas las invocaciones que provienen de beans de Spring propios del framework o de librerías de terceros. Es el filtro más barato posible y elimina la gran mayoría de las invocaciones que el pointcut captura pero que no son de la aplicación.
Las invocaciones que pasan ese filtro enfrentan la evaluación de patrones, protegida por el cache:
String cacheKey = packageName + "." + className + "#" + methodName;
Optional<PatternConfig> matchedPattern = matchCache.computeIfAbsent(
cacheKey,
k -> findMatchingPattern(packageName, className, methodName));
if (matchedPattern.isEmpty()) {
return joinPoint.proceed();
}Si ningún patrón hace match, la invocación pasa sin ningún registro. Si hay match, el PatternConfig resultante determina todo el comportamiento posterior: nivel de log, umbral de tiempo, y por extensión qué tan visible es esa capa en producción.
La firma comprimida
Cada registro incluye una firma que identifica el método observado. La firma completa de un método en este proyecto puede ocupar una línea entera de log por sí sola. El aspecto la comprime preservando solo la inicial de cada segmento del paquete excepto el último:
private String compressPackage(String packageName) {
if (packageName == null || packageName.isBlank()) return "";
String[] segments = packageName.split("\\.");
if (segments.length == 1) return packageName;
StringBuilder sb = new StringBuilder();
for (int i = 0; i < segments.length - 1; i++) {
sb.append(segments[i].charAt(0)).append('.');
}
sb.append(segments[segments.length - 1]);
return sb.toString();
}El resultado para com.app_247.blog.id202603212000art.infrastructure.drivenadapters.jpa.usuario.adapter es c.a.b.i.i.d.j.u.adapter. El último segmento se preserva completo porque es el que aporta contexto: adapter, usecase, entrypoints. Los segmentos anteriores son el prefijo que cualquier desarrollador del proyecto reconoce por su inicial. La firma completa que aparece en cada registro queda así:
c.a.b.i.i.d.j.u.adapter.UsuarioPersistenciaAdapter#guardarLegible, compacta, y suficientemente precisa para ubicar el método en el árbol de archivos sin ambigüedad.
Los cuatro tipos de registro
El advice @Around tiene visibilidad completa sobre la invocación: puede ejecutar código antes, durante y en el camino de error. Esa visibilidad se materializa en cuatro tipos de registro con marcadores visuales distintos que permiten identificarlos de un vistazo en la consola:
private static final String INPUT_MARKER = ">>> [INPUT] |";
private static final String OUTPUT_MARKER = "<<< [OUTPUT] |";
private static final String TIMING_MARKER = "*** [TIMING] |";
private static final String ERROR_MARKER = "!!! [ERROR] |";
private static final String PROPAGATED_MARKER = "!!! [ERROR-PROPAGATED] |";Los marcadores no son decorativos. En una consola con decenas de líneas por segundo, la diferencia visual entre >>>, <<<, *** y !!! permite al ojo localizar inmediatamente qué tipo de evento está leyendo sin procesar el texto completo de cada línea.
INPUT
El registro INPUT captura los argumentos del método en el momento de la invocación. La lógica recorre los parámetros usando reflexión para asociar cada valor con el nombre del parámetro declarado:
private void logInput(
String methodSignature,
MethodSignature signature,
Object[] args,
PatternConfig pattern) {
Parameter[] parameters = signature.getMethod().getParameters();
if (parameters.length == 0) {
logAtLevel(pattern, "{} {} args: (none)", methodSignature, INPUT_MARKER);
return;
}
Map<String, Object> inputMap = new LinkedHashMap<>();
IntStream.range(0, parameters.length)
.forEach(i -> inputMap.put(
parameters[i].getName(),
formatArg(args[i])));
logAtLevel(pattern, "{} {} args: {}", methodSignature, INPUT_MARKER, inputMap);
}LinkedHashMap preserva el orden de inserción, que coincide con el orden de declaración de los parámetros. El resultado en el log es un mapa legible donde cada clave es el nombre exacto del parámetro y cada valor es la representación JSON del argumento. Para que los nombres de los parámetros estén disponibles en tiempo de ejecución a través de parameter.getName(), el proyecto debe compilarse con la opción -parameters. En Spring Boot esto está habilitado por defecto desde la versión 3.2, así que en este stack no requiere ninguna configuración adicional.
La serialización de cada argumento pasa por formatArg:
private String formatArg(Object arg) {
if (arg == null) return "null";
try {
return objectMapper.writeValueAsString(arg);
} catch (Exception e) {
e.printStackTrace();
return arg.toString();
}
}Si Jackson no puede serializar el objeto, el método cae de vuelta a toString() como último recurso. Esto evita que un argumento no serializable rompa el flujo de logging y, por extensión, el flujo de negocio. El aspecto es un observador: nunca debe interferir con la ejecución que está observando.
OUTPUT
El registro OUTPUT captura el valor de retorno una vez que el método completa su ejecución normalmente:
private void logOutput(
String methodSignature,
Class<?> returnType,
Object result,
PatternConfig pattern) {
if (void.class.equals(returnType) || Void.class.equals(returnType)) {
logAtLevel(pattern, "{} {} return: void", methodSignature, OUTPUT_MARKER);
return;
}
logAtLevel(pattern, "{} {} return: {}",
methodSignature, OUTPUT_MARKER, formatArg(result));
}El caso especial es cuando el tipo de retorno es void: no hay nada que serializar, pero sí vale la pena registrar que el método completó su ejecución. Un registro OUTPUT ausente en un flujo donde se esperaba puede ser la primera pista de que algo no terminó correctamente.
TIMING
El registro TIMING es el más rico en información operacional. Se emite siempre, tanto en el flujo normal como en el flujo de error, lo que garantiza que siempre hay una métrica de tiempo disponible independientemente de cómo terminó la ejecución:
private void logTiming(
String methodSignature,
Instant start,
Instant end,
long elapsedMs,
PatternConfig pattern) {
String startStr = formatInstant(start);
String endStr = formatInstant(end);
String elapsedFormatted = formatElapsed(elapsedMs);
if (elapsedMs >= pattern.getWarnThresholdMs()) {
log.warn("{} {} start: {} | end: {} | elapsed: {} ⚠️ superó umbral de {}ms",
methodSignature, TIMING_MARKER,
startStr, endStr,
elapsedFormatted,
pattern.getWarnThresholdMs());
return;
}
logAtLevel(pattern, "{} {} start: {} | end: {} | elapsed: {}",
methodSignature, TIMING_MARKER, startStr, endStr, elapsedFormatted);
}La lógica del umbral merece atención: si elapsedMs supera warnThresholdMs, el registro se emite en WARN directamente con log.warn(), ignorando el nivel configurado en el patrón. Esto significa que aunque el adapter tenga log-level=DEBUG y en producción sus logs normales sean invisibles, un TIMING que supere el umbral siempre aparece en INFO y superior. La lentitud es siempre visible, independientemente del nivel de verbosidad configurado para esa capa.
El tiempo se formatea de forma legible según su magnitud:
private String formatElapsed(long elapsedMs) {
if (elapsedMs < 1_000) {
return elapsedMs + "ms";
} else if (elapsedMs < 60_000) {
return "%.3fs".formatted(elapsedMs / 1_000.0);
} else {
long minutes = elapsedMs / 60_000;
long seconds = (elapsedMs % 60_000) / 1_000;
long millis = elapsedMs % 1_000;
return "%dm %ds %dms".formatted(minutes, seconds, millis);
}
}Menos de un segundo se muestra en milisegundos: 120ms. Entre un segundo y un minuto se muestra con tres decimales: 1.234s. Por encima de un minuto se desglosa en componentes: 2m 3s 456ms. Esta progresión hace que el número sea siempre legible en la unidad que le corresponde, sin que el ojo tenga que convertir 120000ms a 2 minutos mentalmente.
Los instantes de inicio y fin se formatean con precisión de milisegundos:
private static final DateTimeFormatter FORMATTER =
DateTimeFormatter.ofPattern("HH:mm:ss.SSS");
private String formatInstant(Instant instant) {
return LocalDateTime
.ofInstant(instant, ZoneId.systemDefault())
.format(FORMATTER);
}El resultado en el log es start: 15:47:05.750 | end: 15:47:05.870 | elapsed: 120ms. Con esos tres valores en cada registro TIMING es posible reconstruir la línea de tiempo completa de una transacción sin necesidad de ninguna herramienta externa: basta con ordenar los registros por hora de inicio y la secuencia de etapas queda visible.
ERROR y ERROR-PROPAGATED
El manejo de errores es donde el diseño del aspecto muestra su complejidad más interesante. El problema a resolver es este: cuando una excepción sube por el stack, cada capa interceptada la captura en su bloque catch, lo que sin ningún mecanismo de control produciría un registro ERROR en cada capa que la excepción atraviesa. En el flujo del proyecto de ejemplo, una BusinessException lanzada en el UseCase sería logueada como ERROR tanto en el UseCase como en el Controller, duplicando la información y contaminando los dashboards con falsos positivos.
La solución usa dos ThreadLocal que trabajan juntos:
private static final ThreadLocal<Throwable> loggedExceptionHolder = new ThreadLocal<>();
private static final ThreadLocal<Integer> depthHolder =
ThreadLocal.withInitial(() -> 0);depthHolder cuenta cuántos métodos interceptados están activos simultáneamente en el stack del hilo actual. Se incrementa al entrar a cada método interceptado y se decrementa al salir, tanto en el flujo normal como en el flujo de error. loggedExceptionHolder almacena una referencia a la excepción que ya fue logueada como ERROR origen.
La lógica en el bloque de error funciona así:
} catch (Throwable ex) {
Instant endInstant = Instant.now();
long elapsed = endInstant.toEpochMilli() - startInstant.toEpochMilli();
if (loggedExceptionHolder.get() == null) {
loggedExceptionHolder.set(ex);
logException(methodSignature, ex, elapsed, ERROR_MARKER);
} else {
logException(methodSignature, ex, elapsed, PROPAGATED_MARKER);
}
logTiming(methodSignature, startInstant, endInstant, elapsed, pattern);
int currentDepth = depthHolder.get() - 1;
depthHolder.set(currentDepth);
if (currentDepth == 0) {
loggedExceptionHolder.remove();
depthHolder.remove();
}
throw ex;
}La primera capa interceptada que captura la excepción encuentra loggedExceptionHolder vacío, la registra con ERROR_MARKER y la almacena en el holder. Cada capa superior que captura la misma excepción encuentra el holder poblado y la registra con PROPAGATED_MARKER en nivel DEBUG. En la consola, el ERROR aparece exactamente una vez, en el punto donde se originó el problema, y las capas superiores emiten un DEBUG discreto que confirma la propagación sin duplicar el ruido.
La limpieza de los ThreadLocal ocurre cuando depthHolder llega a cero, es decir, cuando el método más externo del stack interceptado termina su manejo del error. Este punto de limpieza es crítico: los hilos en un servidor web son reutilizados de un request al siguiente a través de un pool. Si los ThreadLocal no se limpian, el hilo llega al siguiente request con valores residuales del request anterior. El efecto concreto sería que la primera excepción del nuevo request encontraría loggedExceptionHolder ya poblado y se registraría como ERROR-PROPAGATED en lugar de ERROR, perdiendo el origen real del error. Es un bug silencioso que solo aparece bajo carga, cuando los hilos se reutilizan frecuentemente, y que es extremadamente difícil de reproducir en desarrollo.
La razón por la que depthHolder es necesario además de loggedExceptionHolder es precisamente esta: no basta con saber que hay una excepción registrada; hay que saber cuándo es seguro limpiarla. Sin el contador de profundidad, el aspecto no puede distinguir entre el momento en que la excepción está siendo propagada por capas internas, donde el holder debe mantenerse, y el momento en que salió completamente del stack interceptado, donde el holder debe limpiarse.
El método que emite el registro de error diferencia los dos casos:
private void logException(
String methodSignature,
Throwable ex,
long elapsedMs,
String marker) {
if (marker.equals(PROPAGATED_MARKER)) {
log.debug("{} {} exception: {} - {} | elapsed: {}",
methodSignature,
marker,
ex.getClass().getSimpleName(),
ex.getMessage(),
formatElapsed(elapsedMs));
} else {
log.error("{} {} exception: {} - {} | elapsed: {}",
methodSignature,
marker,
ex.getClass().getSimpleName(),
ex.getMessage(),
formatElapsed(elapsedMs));
}
}El ERROR origen siempre se emite en nivel ERROR, independientemente del nivel configurado en el patrón. La propagación se emite en DEBUG para que en producción con nivel INFO sea completamente invisible. Si se necesita ver la cadena de propagación para diagnosticar un problema, basta con activar DEBUG dinámicamente.
El flujo completo bajo la lupa
Con todos los componentes descritos, vale la pena recorrer la salida de consola real del proyecto para el flujo feliz y para el flujo de error. No como validación de que el código funciona, sino como lectura del sistema contando su propia historia.
Flujo feliz: registro exitoso de un usuario
La solicitud llega al Controller con nombre, email y edad. El aspecto captura la invocación antes de que el método ejecute su primera línea y emite el INPUT con los argumentos serializados:
INFO : c.a.b.i.i.e.a.registrarusuario.RegistrarUsuarioController#registrar
>>> [INPUT] | args: {request={"nombre":"Juan Perez","email":"[email protected]","edad":25}}El Controller mapea el request a un RegistrarUsuarioIn e invoca el UseCase. El aspecto intercepta esa invocación también y emite el INPUT del UseCase con el comando ya mapeado:
INFO : c.a.b.i.d.u.registrarusuario.RegistrarUsuarioUseCase#ejecutar
>>> [INPUT] | args: {command={"nombre":"Juan Perez","email":"[email protected]","edad":25}}Dentro del UseCase ocurren las validaciones de dominio: NombreValidator, EdadValidator y EmailDominioValidator se invocan secuencialmente. Son clases planas sin anotaciones de Spring, no son beans, y el aspecto no las ve. Su comportamiento queda implícito en el contexto del UseCase que las llama. Si alguna lanzara una excepción, aparecería en el log del UseCase como un ERROR, no en un log propio del validador.
Superadas las validaciones, el UseCase llama a gateway.existeEmail(). Spring resuelve esa llamada hacia UsuarioPersistenciaAdapter, que sí es un bean y sí está interceptado:
DEBUG : c.a.b.i.i.d.j.u.adapter.UsuarioPersistenciaAdapter#existeEmail
>>> [INPUT] | args: {email="[email protected]"}
DEBUG : c.a.b.i.i.d.j.u.adapter.UsuarioPersistenciaAdapter#existeEmail
<<< [OUTPUT] | return: false
WARN : c.a.b.i.i.d.j.u.adapter.UsuarioPersistenciaAdapter#existeEmail
*** [TIMING] | start: 15:47:05.750 | end: 15:47:05.870 | elapsed: 120ms ⚠️ superó umbral de 100msTres registros para una sola llamada al adapter. El INPUT muestra exactamente qué email se consultó. El OUTPUT confirma que no existe. El TIMING revela que la operación tardó 120ms, superando el umbral de 100ms configurado para esta capa, lo que eleva automáticamente el registro a WARN aunque el nivel configurado para el adapter sea DEBUG. Este WARN es visible en producción con nivel INFO aunque todos los demás registros del adapter sean invisibles. La lentitud siempre se ve.
El UseCase continúa: genera el username, construye el objeto Usuario y llama a gateway.guardar(). El adapter es interceptado de nuevo:
DEBUG : c.a.b.i.i.d.j.u.adapter.UsuarioPersistenciaAdapter#guardar
>>> [INPUT] | args: {usuario={"id":null,"nombre":"Juan Perez","email":"[email protected]","edad":25,"username":"juanperez","fechaRegistro":"2026-05-18T15:47:05.8756894"}}
DEBUG : c.a.b.i.i.d.j.u.adapter.UsuarioPersistenciaAdapter#guardar
<<< [OUTPUT] | return: {"id":1,"nombre":"Juan Perez","email":"[email protected]","edad":25,"username":"juanperez","fechaRegistro":"2026-05-18T15:47:05.8756894"}
DEBUG : c.a.b.i.i.d.j.u.adapter.UsuarioPersistenciaAdapter#guardar
*** [TIMING] | start: 15:47:05.877 | end: 15:47:05.939 | elapsed: 62msEl INPUT del guardar muestra el objeto completo antes de persistirse, con id en null porque todavía no ha pasado por la base de datos. El OUTPUT muestra el mismo objeto con el id asignado por H2 ya presente. El TIMING marca 62ms, dentro del umbral de 100ms, así que se emite en DEBUG normal.
El UseCase completa su ejecución y retorna el RegistrarUsuarioOut. El aspecto lo captura:
INFO : c.a.b.i.d.u.registrarusuario.RegistrarUsuarioUseCase#ejecutar
<<< [OUTPUT] | return: {"id":1,"nombre":"Juan Perez","email":"[email protected]","username":"juanperez","fechaRegistro":"2026-05-18T15:47:05.8756894"}
INFO : c.a.b.i.d.u.registrarusuario.RegistrarUsuarioUseCase#ejecutar
*** [TIMING] | start: 15:47:05.748 | end: 15:47:05.940 | elapsed: 192msEl OUTPUT del UseCase no incluye el campo edad porque RegistrarUsuarioOut no lo tiene: ese DTO de salida solo expone lo que el contrato del caso de uso devuelve. El TIMING del UseCase registra 192ms totales de orquestación, que incluyen las validaciones, las dos llamadas al adapter y la construcción de objetos intermedios.
Finalmente el Controller recibe el resultado, lo mapea a RegistrarUsuarioResponse y retorna:
INFO : c.a.b.i.i.e.a.registrarusuario.RegistrarUsuarioController#registrar
<<< [OUTPUT] | return: {"id":1,"nombre":"Juan Perez","email":"[email protected]","username":"juanperez","fechaRegistro":"2026-05-18T15:47:05.8756894","mensaje":"Usuario registrado exitosamente"}
INFO : c.a.b.i.i.e.a.registrarusuario.RegistrarUsuarioController#registrar
*** [TIMING] | start: 15:47:05.747 | end: 15:47:05.944 | elapsed: 197msEl OUTPUT del Controller incluye el campo mensaje que RegistrarUsuarioResponse agrega al mapear desde el RegistrarUsuarioOut. El TIMING del Controller registra 197ms de extremo a extremo, 5ms más que el UseCase, que es exactamente el overhead del Controller en mappers y serialización de la respuesta HTTP.
Con esos once registros, sin ninguna línea de log escrita en ninguna clase del proyecto, el sistema cuenta su historia completa: qué llegó, por qué capas pasó, cuánto tardó cada una, y qué salió.
Flujo de error: email duplicado
La misma solicitud llega por segunda vez. El Controller y el UseCase emiten sus INPUT normalmente, idénticos a los del flujo feliz. El adapter consulta si el email existe:
DEBUG : c.a.b.i.i.d.j.u.adapter.UsuarioPersistenciaAdapter#existeEmail
>>> [INPUT] | args: {email="[email protected]"}
DEBUG : c.a.b.i.i.d.j.u.adapter.UsuarioPersistenciaAdapter#existeEmail
<<< [OUTPUT] | return: true
DEBUG : c.a.b.i.i.d.j.u.adapter.UsuarioPersistenciaAdapter#existeEmail
*** [TIMING] | start: 15:47:12.883 | end: 15:47:12.887 | elapsed: 4msEsta vez el OUTPUT es true. El adapter completó su ejecución normalmente: encontró el email, retornó el resultado, el aspecto registró el TIMING. Hasta aquí no hay ningún error. El error ocurre en el UseCase, que recibe el true y lanza la BusinessException:
ERROR : c.a.b.i.d.u.registrarusuario.RegistrarUsuarioUseCase#ejecutar
!!! [ERROR] | exception: BusinessException - El email ya está registrado | elapsed: 4ms
INFO : c.a.b.i.d.u.registrarusuario.RegistrarUsuarioUseCase#ejecutar
*** [TIMING] | start: 15:47:12.883 | end: 15:47:12.887 | elapsed: 4msDos registros para el camino de error del UseCase. El ERROR captura el tipo de excepción y su mensaje, que en este caso es suficientemente descriptivo para entender qué ocurrió sin necesidad de un stacktrace. El TIMING se emite de todas formas: 4ms desde que entró el comando hasta que la excepción salió del UseCase. Nótese que no hay OUTPUT: el método no completó normalmente, así que el aspecto nunca llega al código que lo emite. La ausencia del OUTPUT es en sí misma información.
La excepción sube al Controller. El aspecto la intercepta, encuentra loggedExceptionHolder ya poblado por el UseCase, y la registra como propagación:
DEBUG : c.a.b.i.i.e.a.registrarusuario.RegistrarUsuarioController#registrar
!!! [ERROR-PROPAGATED] | exception: BusinessException - El email ya está registrado | elapsed: 5ms
INFO : c.a.b.i.i.e.a.registrarusuario.RegistrarUsuarioController#registrar
*** [TIMING] | start: 15:47:12.883 | end: 15:47:12.888 | elapsed: 5msEl ERROR-PROPAGATED se emite en DEBUG, invisible en producción con nivel INFO. El TIMING del Controller registra 5ms de extremo a extremo, 1ms más que el UseCase, que es el overhead del propio Controller antes de invocar el UseCase.
Desde el Controller la excepción sigue subiendo hasta el GlobalExceptionHandler, que la captura y construye la respuesta de error apropiada. El handler no está interceptado por el aspecto porque no tiene ninguno de los estereotipos del pointcut que coincida con un patrón configurado, así que su ejecución es completamente silenciosa desde el punto de vista del sistema de logs. El cliente recibe un HTTP 409 con el detalle del error.
Lo que este flujo demuestra es la distinción que se anticipó en la primera parte: un ERROR en el log del aspecto no siempre significa un fallo del sistema. Una BusinessException por email duplicado es una condición esperada del negocio. En un dashboard de monitoreo, filtrar por ERROR en los logs del aspecto va a incluir estos casos junto con los errores reales de infraestructura. La forma de separar ambos tipos es observar de dónde viene el ERROR: si viene de un UseCase lanzando una excepción de negocio, es ruido operacional esperado; si viene de un adapter fallando al conectar con la base de datos, es un problema genuino que requiere atención. El campo de la firma en el registro, que incluye la capa y la clase, es la clave para hacer esa distinción.
Producción sin redespliegue
Hay un escenario que todo sistema productivo enfrenta eventualmente: un comportamiento anómalo que no se reproduce en desarrollo y que requiere ver el detalle de las capas internas para diagnosticarse. En el modelo tradicional, la respuesta era subir el nivel de log a DEBUG, redesplegar, reproducir el problema, bajar el nivel, redesplegar de nuevo. En sistemas con tráfico real ese ciclo puede tomar horas y el volumen de logs generado puede saturar la infraestructura de observabilidad.
El diseño de este sistema evita ese ciclo de dos formas complementarias. La primera es estructural: los logs del adapter están en DEBUG por configuración, así que en producción con nivel INFO son completamente invisibles sin ningún costo operativo. No hay nada que desactivar porque nunca estuvieron activos. La segunda es dinámica: Spring Boot Actuator expone un endpoint que permite cambiar el nivel de log de cualquier paquete en tiempo de ejecución sin reiniciar la aplicación.
Para activarlo basta con incluir Actuator en las dependencias y exponer el endpoint de loggers en la configuración:
management.endpoints.web.exposure.include=loggers
management.endpoint.loggers.enabled=trueCon eso disponible, activar DEBUG para el paquete de los adapters en un ambiente productivo es una llamada HTTP:
POST /actuator/loggers/com.app_247.blog.id202603212000art.infrastructure.drivenadapters
Content-Type: application/json
{"configuredLevel": "DEBUG"}A partir de ese momento, todos los registros del adapter que estaban silenciados aparecen en el log en tiempo real. Cuando el diagnóstico termina, una segunda llamada restaura el nivel a INFO y el silencio vuelve. Sin redespliegue, sin ventana de mantenimiento, sin riesgo de introducir cambios mientras se investiga un problema.
Este mecanismo refleja una filosofía más amplia que vale la pena nombrar explícitamente: el sistema de observabilidad debe poder adaptarse al momento sin modificar el sistema que está observando. La configuración por niveles y los patrones por capa son precisamente el mecanismo que hace eso posible.
Lo que se gana con este diseño
Vale la pena hacer explícito el inventario de lo que este sistema aporta, porque no todo es inmediatamente visible en el código.
La consistencia es quizás el beneficio más silencioso. Cada método interceptado produce exactamente el mismo formato de registro, con los mismos marcadores, la misma estructura de tiempo y la misma firma comprimida. No importa quién escribió la clase ni cuándo: el sistema de logs tiene siempre el mismo aspecto. En un equipo donde varias personas trabajan en paralelo sobre distintas partes del proyecto, esa consistencia es la diferencia entre un log que se puede leer y uno que requiere interpretación caso a caso.
La herencia automática es el segundo beneficio. Cada nueva clase que se añada al proyecto y que cumpla con los patrones configurados, un nuevo UseCase, un nuevo adapter, un nuevo Controller, hereda la observabilidad completa sin que nadie tenga que recordar añadir ninguna instrucción de log. El sistema crece y la observabilidad crece con él.
La separación de responsabilidades es el tercero. La lógica de negocio no sabe que está siendo observada. Los validadores de dominio no importan ninguna librería de logging. El UseCase no tiene ninguna instrucción de log. Si en el futuro el equipo decide cambiar el formato de los registros, añadir un campo nuevo a cada entrada, o integrar el sistema con OpenTelemetry, ese cambio ocurre en un único lugar: MethodLoggingAspect. Ninguna clase de negocio necesita ser modificada.
La granularidad controlable es el cuarto beneficio. El sistema tiene tres niveles de visibilidad configurables de forma independiente: los logs del Controller y el UseCase son INFO y siempre visibles, los logs del adapter son DEBUG y silenciosos en producción, y los WARN de latencia son siempre visibles independientemente del nivel de su capa. Esta estratificación permite operar en producción con un volumen de logs manejable mientras se mantiene la capacidad de activar el detalle completo en segundos cuando se necesita.
Mirando hacia adelante
Lo construido en este artículo es un sistema completo y funcional, pero no es un punto de llegada. Hay líneas naturales de evolución que vale la pena tener en el horizonte.
La más inmediata es el enmascaramiento de datos sensibles, que será el tema de la tercera parte de esta serie. El sistema actual serializa los argumentos y resultados tal como son: un email aparece en el log como texto plano, un número de identificación aparece completo. En muchos contextos eso es inaceptable desde el punto de vista de privacidad y cumplimiento regulatorio. La solución es extender el ObjectMapper que usa el aspecto con un introspector personalizado que lea anotaciones declaradas en el modelo de dominio y aplique estrategias de enmascaramiento antes de escribir el registro. El modelo de dominio declara qué es sensible; el sistema de logs lo respeta automáticamente.
Más allá del enmascaramiento, la integración con OpenTelemetry es otra extensión natural. Los registros estructurados que produce este sistema, con sus marcadores de capa y sus métricas de tiempo, son completamente compatibles con el modelo de spans de OpenTelemetry. Los mismos puntos de interceptación del aspecto que hoy emiten registros de texto podrían emitir spans instrumentados que una plataforma como Jaeger o Zipkin renderiza como árboles de llamadas con tiempos y metadatos. La transición no requeriría cambios en ninguna clase de negocio: solo en el aspecto.
La generación de métricas de aplicación a través de Micrometer desde los mismos puntos de intercepción es otra línea de evolución que elimina la duplicación entre el sistema de logs y el sistema de métricas. Hoy, para saber la latencia promedio de un adapter externo se necesita parsear los registros TIMING. Con Micrometer integrado en el aspecto, ese mismo dato podría alimentar un contador o un histograma directamente, sin pasar por texto. Una única fuente de verdad para logs y métricas, gestionada desde el mismo componente transversal.
Lo que todo esto ilustra, más allá de los detalles técnicos, es que un sistema de observabilidad diseñado con los mismos principios que se aplican a la lógica de negocio, separación de responsabilidades, consistencia, configurabilidad, no es una carga que el equipo arrastra sino una ventaja que el equipo usa. El código del proyecto queda limpio, la observabilidad queda centralizada, y la capacidad de entender qué está pasando en producción en cualquier momento queda disponible sin adivinar y sin redesplegar.
Anexo: Código fuente completo
Las clases que siguen son exactamente las que forman el sistema de logs. Todo lo demás, los validadores, los mappers, las entidades JPA, el handler de excepciones, es lógica del proyecto de ejemplo que no tiene ninguna relación con el sistema de observabilidad y que se puede reemplazar por la lógica propia de cualquier proyecto sin afectar el funcionamiento del aspecto.
Estructura de carpetas
src/main/java/com/app_247/blog/id202603212000art/
│
├── Id202603212000artApplication.java ★
│
└── applications/
└── aop/
├── aspect/
│ └── MethodLoggingAspect.java ★
└── config/
├── JacksonConfig.java ★
└── LoggingAopProperties.java ★
src/main/resources/
└── application.properties ★Cinco artefactos. Tres en el paquete applications/aop, uno en la raíz de la aplicación y uno en recursos. Todo el sistema de observabilidad vive en esas cinco piezas.
Grupo 1 — Propiedades de configuración
LoggingAopProperties.java
package com.app_247.blog.id202603212000art.applications.aop.config;
import java.util.List;
import org.springframework.boot.context.properties.ConfigurationProperties;
import lombok.Data;
@Data
@ConfigurationProperties(prefix = "logging.aop")
public class LoggingAopProperties {
/** Habilita o deshabilita el aspecto completo */
private boolean enabled = true;
/** Paquete raíz de la aplicación, primer filtro antes de evaluar regex */
private String basePackage = "com.app_247.blog.id202603212000art";
/** Lista de patrones de interceptación */
private List<PatternConfig> patterns = List.of();
@Data
public static class PatternConfig {
/** Regex que debe cumplir el paquete completo */
private String packageRegex = ".*";
/** Regex que debe cumplir el nombre simple de la clase */
private String classRegex = ".*";
/** Regex que debe cumplir el nombre del método */
private String methodRegex = ".*";
/** Nivel de log: TRACE, DEBUG, INFO, WARN, ERROR */
private String logLevel = "INFO";
/** Umbral en ms a partir del cual se emite un WARN de tiempo */
private long warnThresholdMs = 500L;
}
}Grupo 2 — Configuración de Jackson
JacksonConfig.java
package com.app_247.blog.id202603212000art.applications.aop.config;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.fasterxml.jackson.databind.SerializationFeature;
import com.fasterxml.jackson.datatype.jsr310.JavaTimeModule;
@Configuration
public class JacksonConfig {
@Bean
public ObjectMapper objectMapper() {
ObjectMapper mapper = new ObjectMapper();
mapper.registerModule(new JavaTimeModule());
mapper.disable(SerializationFeature.WRITE_DATES_AS_TIMESTAMPS);
return mapper;
}
}Grupo 3 — El aspecto
MethodLoggingAspect.java
package com.app_247.blog.id202603212000art.applications.aop.aspect;
import java.lang.reflect.Method;
import java.lang.reflect.Parameter;
import java.time.Instant;
import java.time.LocalDateTime;
import java.time.ZoneId;
import java.time.format.DateTimeFormatter;
import java.util.LinkedHashMap;
import java.util.Map;
import java.util.Optional;
import java.util.concurrent.ConcurrentHashMap;
import java.util.stream.IntStream;
import org.aspectj.lang.ProceedingJoinPoint;
import org.aspectj.lang.annotation.Around;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.reflect.MethodSignature;
import org.springframework.boot.autoconfigure.condition.ConditionalOnProperty;
import org.springframework.stereotype.Component;
import com.app_247.blog.id202603212000art.applications.aop.config.LoggingAopProperties;
import com.app_247.blog.id202603212000art.applications.aop.config.LoggingAopProperties.PatternConfig;
import com.fasterxml.jackson.databind.ObjectMapper;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
@Slf4j
@Aspect
@Component
@RequiredArgsConstructor
@ConditionalOnProperty(prefix = "logging.aop", name = "enabled", havingValue = "true", matchIfMissing = true)
public class MethodLoggingAspect {
private final ObjectMapper objectMapper;
private final LoggingAopProperties properties;
// -------------------------------------------------------------------------
// Marcadores visuales
// -------------------------------------------------------------------------
private static final String INPUT_MARKER = ">>> [INPUT] |";
private static final String OUTPUT_MARKER = "<<< [OUTPUT] |";
private static final String TIMING_MARKER = "*** [TIMING] |";
private static final String ERROR_MARKER = "!!! [ERROR] |";
private static final String PROPAGATED_MARKER = "!!! [ERROR-PROPAGATED] |";
private static final DateTimeFormatter FORMATTER =
DateTimeFormatter.ofPattern("HH:mm:ss.SSS");
// -------------------------------------------------------------------------
// ThreadLocal: registra la excepción que ya fue logueada como ERROR origen
// evita que capas superiores la vuelvan a loguear como ERROR
// -------------------------------------------------------------------------
private static final ThreadLocal<Throwable> loggedExceptionHolder =
new ThreadLocal<>();
// -------------------------------------------------------------------------
// ThreadLocal: contador de profundidad de métodos interceptados activos
// permite saber cuándo estamos en el método más externo del stack
// -------------------------------------------------------------------------
private static final ThreadLocal<Integer> depthHolder =
ThreadLocal.withInitial(() -> 0);
// -------------------------------------------------------------------------
// Cache de matching por firma de método
// Key: "com.app_247...RegistrarUsuarioUseCase#ejecutar"
// Value: PatternConfig que hizo match, o empty si no hubo match
// -------------------------------------------------------------------------
private final ConcurrentHashMap<String, Optional<PatternConfig>> matchCache =
new ConcurrentHashMap<>();
// -------------------------------------------------------------------------
// Pointcut: limitado a beans Spring, excluye el propio paquete aop
// -------------------------------------------------------------------------
@Around("(within(@org.springframework.stereotype.Service *) " +
"|| within(@org.springframework.stereotype.Component *) " +
"|| within(@org.springframework.web.bind.annotation.RestController *)" +
"|| within(@org.springframework.stereotype.Repository *)) " +
"&& !within(com.app_247.blog.id202603212000art.aop..*)")
public Object logMethod(ProceedingJoinPoint joinPoint) throws Throwable {
MethodSignature signature = (MethodSignature) joinPoint.getSignature();
Method method = signature.getMethod();
String packageName = method.getDeclaringClass().getPackageName();
String className = method.getDeclaringClass().getSimpleName();
String methodName = method.getName();
// Filtro rápido por paquete base antes de evaluar regex
if (!packageName.startsWith(properties.getBasePackage())) {
return joinPoint.proceed();
}
// Cache de matching: evita re-evaluar regex en invocaciones repetidas
String cacheKey = packageName + "." + className + "#" + methodName;
Optional<PatternConfig> matchedPattern = matchCache.computeIfAbsent(
cacheKey,
k -> findMatchingPattern(packageName, className, methodName));
if (matchedPattern.isEmpty()) {
return joinPoint.proceed();
}
PatternConfig pattern = matchedPattern.get();
// Firma comprimida:
// c.a.b.i.d.u.registrarusuario.RegistrarUsuarioUseCase#ejecutar
String methodSignature = "%s.%s#%s".formatted(
compressPackage(packageName),
className,
methodName);
// Incrementar profundidad al entrar en un método interceptado
depthHolder.set(depthHolder.get() + 1);
logInput(methodSignature, signature, joinPoint.getArgs(), pattern);
Instant startInstant = Instant.now();
Object result;
try {
result = joinPoint.proceed();
} catch (Throwable ex) {
Instant endInstant = Instant.now();
long elapsed = endInstant.toEpochMilli() - startInstant.toEpochMilli();
if (loggedExceptionHolder.get() == null) {
// Primera captura → origen del error
loggedExceptionHolder.set(ex);
logException(methodSignature, ex, elapsed, ERROR_MARKER);
} else {
// Ya fue logueada más abajo → propagación
logException(methodSignature, ex, elapsed, PROPAGATED_MARKER);
}
logTiming(methodSignature, startInstant, endInstant, elapsed, pattern);
// Decrementar profundidad al salir con excepción
int currentDepth = depthHolder.get() - 1;
depthHolder.set(currentDepth);
// Limpiar ThreadLocals solo cuando salimos del método más externo
if (currentDepth == 0) {
loggedExceptionHolder.remove();
depthHolder.remove();
}
throw ex;
}
Instant endInstant = Instant.now();
long elapsed = endInstant.toEpochMilli() - startInstant.toEpochMilli();
// Decrementar profundidad al salir en flujo normal
depthHolder.set(depthHolder.get() - 1);
logOutput(methodSignature, method.getReturnType(), result, pattern);
logTiming(methodSignature, startInstant, endInstant, elapsed, pattern);
return result;
}
// -------------------------------------------------------------------------
// Compresión de paquete
// com.app_247.blog.id202603212000art.domain.usecase.registrarusuario
// → c.a.b.i.d.u.registrarusuario
// -------------------------------------------------------------------------
private String compressPackage(String packageName) {
if (packageName == null || packageName.isBlank()) return "";
String[] segments = packageName.split("\\.");
if (segments.length == 1) return packageName;
StringBuilder sb = new StringBuilder();
for (int i = 0; i < segments.length - 1; i++) {
sb.append(segments[i].charAt(0)).append('.');
}
sb.append(segments[segments.length - 1]);
return sb.toString();
}
// -------------------------------------------------------------------------
// Busca el primer patrón configurado que haga match con el método
// -------------------------------------------------------------------------
private Optional<PatternConfig> findMatchingPattern(
String packageName,
String className,
String methodName) {
return properties.getPatterns()
.stream()
.filter(pattern -> packageName.matches(pattern.getPackageRegex())
&& className.matches(pattern.getClassRegex())
&& methodName.matches(pattern.getMethodRegex()))
.findFirst();
}
// -------------------------------------------------------------------------
// Log INPUT
// -------------------------------------------------------------------------
private void logInput(
String methodSignature,
MethodSignature signature,
Object[] args,
PatternConfig pattern) {
Parameter[] parameters = signature.getMethod().getParameters();
if (parameters.length == 0) {
logAtLevel(pattern, "{} {} args: (none)", methodSignature, INPUT_MARKER);
return;
}
Map<String, Object> inputMap = new LinkedHashMap<>();
IntStream.range(0, parameters.length)
.forEach(i -> inputMap.put(
parameters[i].getName(),
formatArg(args[i])));
logAtLevel(pattern, "{} {} args: {}", methodSignature, INPUT_MARKER, inputMap);
}
// -------------------------------------------------------------------------
// Log OUTPUT
// -------------------------------------------------------------------------
private void logOutput(
String methodSignature,
Class<?> returnType,
Object result,
PatternConfig pattern) {
if (void.class.equals(returnType) || Void.class.equals(returnType)) {
logAtLevel(pattern, "{} {} return: void", methodSignature, OUTPUT_MARKER);
return;
}
logAtLevel(pattern, "{} {} return: {}",
methodSignature, OUTPUT_MARKER, formatArg(result));
}
// -------------------------------------------------------------------------
// Log TIMING
// -------------------------------------------------------------------------
private void logTiming(
String methodSignature,
Instant start,
Instant end,
long elapsedMs,
PatternConfig pattern) {
String startStr = formatInstant(start);
String endStr = formatInstant(end);
String elapsedFormatted = formatElapsed(elapsedMs);
if (elapsedMs >= pattern.getWarnThresholdMs()) {
log.warn("{} {} start: {} | end: {} | elapsed: {} ⚠️ superó umbral de {}ms",
methodSignature, TIMING_MARKER,
startStr, endStr,
elapsedFormatted,
pattern.getWarnThresholdMs());
return;
}
logAtLevel(pattern, "{} {} start: {} | end: {} | elapsed: {}",
methodSignature, TIMING_MARKER, startStr, endStr, elapsedFormatted);
}
// -------------------------------------------------------------------------
// Log ERROR / PROPAGATED
// El marcador se recibe como parámetro para distinguir origen de propagación
// Siempre se emite en ERROR independiente del nivel configurado en el patrón
// -------------------------------------------------------------------------
private void logException(
String methodSignature,
Throwable ex,
long elapsedMs,
String marker) {
if (marker.equals(PROPAGATED_MARKER)) {
// Solo informativo — el error real ya fue logueado en el origen
log.debug("{} {} exception: {} - {} | elapsed: {}",
methodSignature,
marker,
ex.getClass().getSimpleName(),
ex.getMessage(),
formatElapsed(elapsedMs));
} else {
// Origen del error — siempre visible
log.error("{} {} exception: {} - {} | elapsed: {}",
methodSignature,
marker,
ex.getClass().getSimpleName(),
ex.getMessage(),
formatElapsed(elapsedMs));
}
}
// -------------------------------------------------------------------------
// Emisión de log según nivel configurado en el patrón
// -------------------------------------------------------------------------
private void logAtLevel(PatternConfig pattern, String message, Object... args) {
switch (pattern.getLogLevel().toUpperCase()) {
case "TRACE" -> log.trace(message, args);
case "DEBUG" -> log.debug(message, args);
case "WARN" -> log.warn(message, args);
case "ERROR" -> log.error(message, args);
default -> log.info(message, args);
}
}
// -------------------------------------------------------------------------
// Helpers
// -------------------------------------------------------------------------
private String formatInstant(Instant instant) {
return LocalDateTime
.ofInstant(instant, ZoneId.systemDefault())
.format(FORMATTER);
}
private String formatElapsed(long elapsedMs) {
if (elapsedMs < 1_000) {
return elapsedMs + "ms";
} else if (elapsedMs < 60_000) {
return "%.3fs".formatted(elapsedMs / 1_000.0);
} else {
long minutes = elapsedMs / 60_000;
long seconds = (elapsedMs % 60_000) / 1_000;
long millis = elapsedMs % 1_000;
return "%dm %ds %dms".formatted(minutes, seconds, millis);
}
}
private String formatArg(Object arg) {
if (arg == null) return "null";
try {
return objectMapper.writeValueAsString(arg);
} catch (Exception e) {
e.printStackTrace();
return arg.toString();
}
}
}Grupo 4 — Bootstrap
Id202603212000artApplication.java
package com.app_247.blog.id202603212000art;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.boot.context.properties.EnableConfigurationProperties;
import com.app_247.blog.id202603212000art.applications.aop.config.LoggingAopProperties;
@SpringBootApplication
@EnableConfigurationProperties(LoggingAopProperties.class)
public class Id202603212000artApplication {
public static void main(String[] args) {
SpringApplication.run(Id202603212000artApplication.class, args);
}
}Grupo 5 — Configuración de la aplicación
application.properties
spring.application.name=id202603212000art
# ================================
# SERVER
# ================================
server.port=8080
# ================================
# H2 DATABASE
# ================================
spring.datasource.url=jdbc:h2:mem:usuariosdb;DB_CLOSE_DELAY=-1;DB_CLOSE_ON_EXIT=FALSE
spring.datasource.driver-class-name=org.h2.Driver
spring.datasource.username=sa
spring.datasource.password=
# H2 Console (http://localhost:8080/h2-console)
spring.h2.console.enabled=true
spring.h2.console.path=/h2-console
# ================================
# JPA / HIBERNATE
# ================================
spring.jpa.database-platform=org.hibernate.dialect.H2Dialect
spring.jpa.hibernate.ddl-auto=create-drop
# ================================
# JACKSON
# ================================
spring.jackson.serialization.write-dates-as-timestamps=false
spring.jackson.time-zone=America/Bogota
# ================================
# AOP LOGGING
# ================================
logging.aop.enabled=true
logging.aop.base-package=com.app_247.blog.id202603212000art
# UseCase
logging.aop.patterns[0].package-regex=com\\.app_247\\.blog\\.id202603212000art\\.domain\\.usecase.*
logging.aop.patterns[0].class-regex=.*UseCase
logging.aop.patterns[0].method-regex=.*
logging.aop.patterns[0].log-level=INFO
logging.aop.patterns[0].warn-threshold-ms=300
# Adapter de persistencia
logging.aop.patterns[1].package-regex=com\\.app_247\\.blog\\.id202603212000art\\.infrastructure\\.drivenadapters.*
logging.aop.patterns[1].class-regex=.*Adapter
logging.aop.patterns[1].method-regex=.*
logging.aop.patterns[1].log-level=DEBUG
logging.aop.patterns[1].warn-threshold-ms=100
# Controller
logging.aop.patterns[2].package-regex=com\\.app_247\\.blog\\.id202603212000art\\.infrastructure\\.entrypoints.*
logging.aop.patterns[2].class-regex=.*Controller
logging.aop.patterns[2].method-regex=.*
logging.aop.patterns[2].log-level=INFO
logging.aop.patterns[2].warn-threshold-ms=500Con esas cinco piezas el sistema está completo. LoggingAopProperties define las reglas, JacksonConfig provee el serializador, MethodLoggingAspect aplica la observabilidad, Id202603212000artApplication registra las propiedades en el contenedor, y application.properties conecta la configuración con el comportamiento deseado para cada capa. Cualquier proyecto que adopte estas cinco piezas y ajuste los patrones a su propia estructura de paquetes tiene el sistema funcionando desde el primer arranque, sin ninguna modificación en las clases de negocio.




























