Cuando un sistema debe ejecutar lo mismo siempre y algo distinto cada vez
- Mauricio ECR
- Arquitectura
- 24 May, 2026
Imagina que estás diseñando el flujo de solicitud de productos financieros de un banco. Un cliente puede pedir una tarjeta de crédito o un crédito para comprar un vehículo. Los dos productos son distintos: tienen pasos diferentes, documentos diferentes, validaciones diferentes. Pero también comparten algo que no puede variar: antes de que cualquier producto se evalúe, el banco necesita saber quién es el cliente, confirmar su identidad y consultar su historial crediticio. Eso ocurre siempre, para cualquier producto, sin excepción.
La pregunta que se presenta de inmediato parece técnica pero es en realidad arquitectónica: ¿dónde vive ese comportamiento compartido? ¿Lo repites en cada flujo de producto? ¿Lo centralizas en algún lugar y los flujos de producto lo invocan? ¿Construyes un flujo único con condicionales que bifurcan la lógica según el tipo de producto?
Cualquiera de esas tres respuestas funciona mientras el sistema es pequeño. El problema aparece cuando el banco decide lanzar un tercer producto, luego un cuarto. Cuando un equipo necesita cambiar la validación de identidad sin tocar los flujos de tarjeta ni de vehículo. Cuando hay que agregar un paso transversal nuevo y ese cambio no puede romper nada de lo que ya está operando. Ahí es donde las soluciones aparentemente razonables revelan su costo real.
Si duplicaste la lógica compartida, ahora debes modificarla en tres o cuatro lugares y confiar en que todos los cambios sean consistentes. Si la centralizaste mediante invocaciones directas, los flujos de producto están acoplados a ese componente central y cualquier cambio en él requiere verificar el impacto en todos los consumidores. Si construiste un flujo con condicionales, cada nuevo producto aumenta la complejidad del núcleo hasta que nadie entiende del todo qué hace ese código.
La tensión es real: hay pasos que deben ejecutarse de forma consistente en toda instancia del flujo, pero cada caso de negocio introduce lógica específica que no puede ni debe generalizarse. Y esa tensión no se resuelve eligiendo uno de los dos lados. Se resuelve separándolos con precisión y definiendo el mecanismo exacto por el que conviven.
La separación que sostiene todo lo demás
El problema que tienen las tres soluciones descritas antes es que todas intentan resolver la tensión desde el mismo lugar: deciden quién ejecuta qué. Una duplica la ejecución, otra la centraliza, otra la condiciona. Pero ninguna se hace la pregunta más profunda: ¿quién tiene el gobierno del flujo en cada momento?
Esa distinción importa porque gobernar el flujo no es lo mismo que ejecutar un paso. Gobernar significa saber en qué punto está el proceso, decidir qué viene después y ser responsable de que el flujo llegue a su fin de forma consistente. Cuando esa responsabilidad está dispersa entre varios componentes que ejecutan partes del proceso, nadie la tiene completamente. Y cuando nadie la tiene completamente, el flujo se fragmenta.
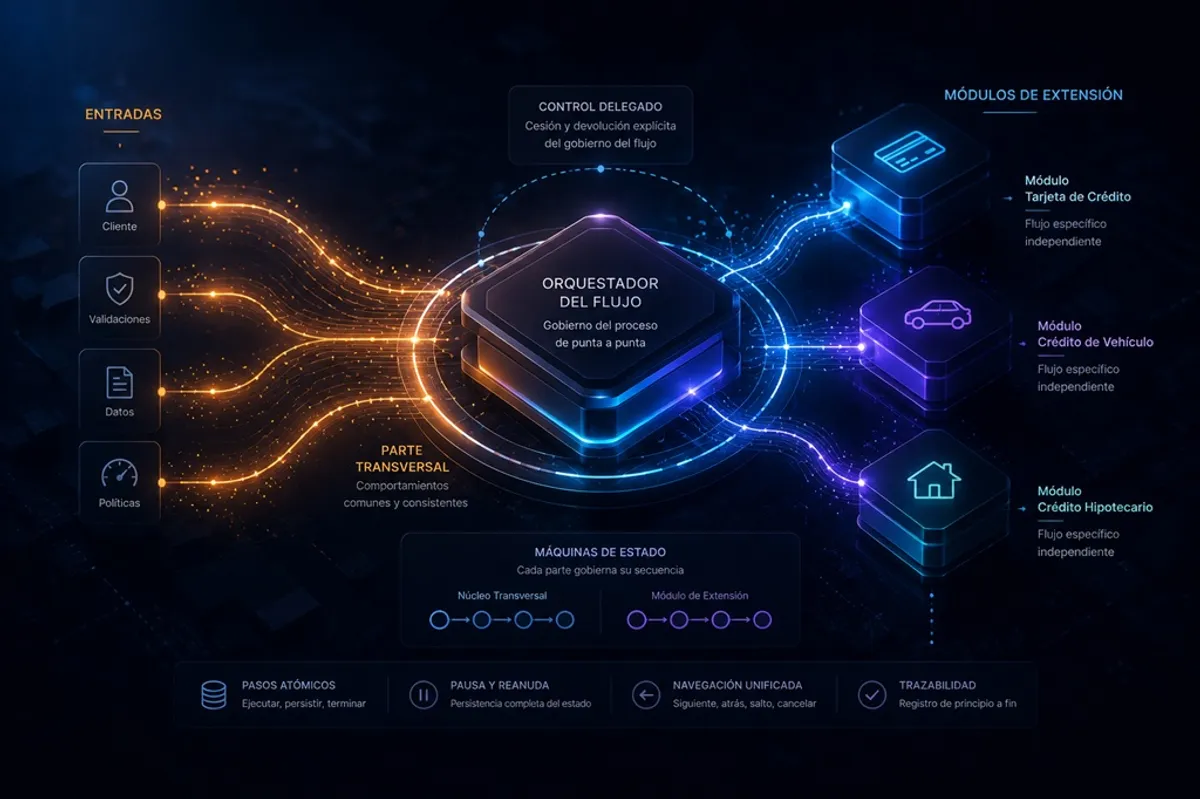
La respuesta natural a ese problema es concentrar el gobierno. Que haya un único responsable del flujo completo que sepa en todo momento dónde está el proceso y qué debe ocurrir a continuación. Ese responsable ejecuta lo que es común a todos los casos y, cuando llega el momento en que cada caso tiene su propia lógica, cede el gobierno temporalmente a quien sabe cómo manejarla. No lo invoca, no lo llama como si fuera una función: le transfiere el control de forma explícita, permanece en espera y lo recupera cuando termina.
Eso es exactamente lo que hace el núcleo transversal: concentra el gobierno del flujo completo, ejecuta los pasos que son comunes a todos los casos y cede el control cuando la especificidad de cada caso debe intervenir. Y eso es exactamente lo que hace un módulo de extensión: recibe ese control, ejecuta la lógica propia de su caso y lo devuelve. El módulo no conoce al núcleo, no depende de él y no lo dirige. Solo sabe que en algún momento va a recibir el gobierno y que cuando termine debe devolverlo.
Para que esa cesión y esa devolución ocurran con precisión, ambas partes necesitan saber en todo momento dónde están y qué viene después. Ese mecanismo es una máquina de estados: un registro del punto exacto en que se encuentra el proceso y un conjunto de transiciones válidas desde ahí. El núcleo tiene la suya, que gobierna sus pasos transversales. Cada módulo tiene la propia, completamente independiente, que gobierna sus pasos específicos. Cuando el núcleo cede el gobierno, su máquina de estados transiciona a un estado que reconoce explícitamente esa cesión. Mientras está en ese estado, cualquier solicitud de navegación que llegue al núcleo es redirigida al módulo activo. Cuando el módulo termina, el núcleo recibe el control de vuelta y su máquina de estados avanza hacia el cierre.
El flujo, visto desde afuera, parece continuo. Visto desde adentro, está compuesto por pasos atómicos: unidades independientes que no conocen ni necesitan conocer los pasos anteriores ni los siguientes. Cada paso se ejecuta, produce un resultado, lo persiste y termina. La secuencia no es responsabilidad del paso, es responsabilidad de la máquina de estados que lo gobierna.
Esa independencia entre pasos le da al flujo algo que los modelos continuos no tienen: la capacidad de pausarse sin romperse. Si un paso necesita información del cliente, el flujo persiste su estado completo y se detiene. Cuando el cliente responde, la máquina de estados retoma exactamente desde donde estaba. Y si el cliente quiere corregir algo que ya ingresó, puede retroceder: la máquina activa, sea la del núcleo o la del módulo, hace la transición hacia atrás y el paso anterior vuelve a estar disponible.
Un núcleo que no cambia pero se adapta
La estabilidad del núcleo es una decisión de diseño, no una limitación técnica. Cuando se incorpora un nuevo producto al banco, el núcleo no se modifica. No necesita saber qué pasos tiene el nuevo módulo, qué validaciones aplica ni qué documentos solicita. Lo único que necesita es que el módulo cumpla un contrato: un acuerdo lógico formal que define las reglas mínimas de interacción entre el núcleo y cualquier módulo que quiera participar del flujo. El módulo no tiene referencia al núcleo ni a otros módulos. Su única dependencia es hacia ese contrato.
Ese contrato es deliberadamente mínimo. En el momento de la cesión, el núcleo no le entrega al módulo un paquete de información recopilada durante la parte transversal. Le entrega una sola cosa: el identificador de la transacción en curso, un identificador único que el núcleo genera cuando el flujo se inicia y que lo acompaña hasta el cierre. Con ese identificador, el módulo puede relacionar cada uno de sus pasos con la transacción correcta. Y si en algún punto de su ejecución necesita información que el núcleo recolectó durante la parte transversal, como los datos del cliente o el resultado de la validación de identidad, la solicita activamente a través de los endpoints que el núcleo expone para ese propósito.
Eso resuelve un problema que los modelos con contratos de entrada ricos suelen enfrentar: si el núcleo evoluciona y empieza a recolectar información nueva, no hay necesidad de modificar el contrato de cesión ni de actualizar los módulos existentes. El núcleo simplemente expone un endpoint nuevo. Los módulos que necesitan esa información lo adoptan cuando lo necesitan. Los que no lo necesitan no saben que existe y no se ven afectados.
Pero la estabilidad del núcleo no significa rigidez. Cuando un módulo se registra, puede declarar una configuración que adapta ciertos comportamientos del núcleo para su caso particular: activar o desactivar capacidades transversales, ajustar ciertas acciones según las respuestas esperadas. La distinción es precisa: el núcleo decide desde su diseño qué aspectos son adaptables y los expone de forma explícita. Un módulo solo puede moverse dentro de ese espacio predefinido, nunca ampliarlo ni redefinirlo. Lo que no fue diseñado como configurable permanece invariante sin importar qué módulo se registre.
Cómo se registra un módulo
Antes de que cualquier flujo pueda ejecutarse, cada módulo debe registrarse en el núcleo. Este proceso ocurre una única vez por módulo y es completamente independiente del flujo de ejecución.
El módulo se presenta ante el componente de registro del núcleo, declara su identidad y entrega su configuración. Como parte de esa configuración, declara también el listado completo de sus pasos: cuántos son y cómo se llama cada uno. Esa información queda almacenada en el núcleo como dato estático y se convierte en la fuente de verdad para el indicador de progreso que verá el cliente durante el flujo. El núcleo valida que el módulo cumpla el contrato de extensión y que su configuración sea válida dentro del espacio de adaptación permitido. Si todo es correcto, el módulo queda disponible para ser invocado.
A partir de ese momento el núcleo sabe que ese módulo existe, cómo debe comportarse cuando sea invocado y cuántos pasos lo componen. No sabe nada más. No conoce la lógica interna del módulo, no puede modificarla y no necesita hacerlo.
Cómo se ejecuta el flujo
Cuando el cliente inicia una solicitud e indica qué producto desea, el núcleo busca el módulo correspondiente, carga su configuración y adapta su comportamiento dentro de los límites predefinidos. Su máquina de estados transiciona al primer estado activo.
El primer paso es el preprocesamiento: el núcleo normaliza y construye el contexto inicial del flujo. En el caso del banco, esto incluye los datos básicos del cliente que llegaron con la solicitud. Al completarse, persiste el estado y la máquina de estados avanza al siguiente paso.
El siguiente paso es la validación transversal. El núcleo confirma la identidad del cliente y consulta su historial crediticio. Si alguna de esas validaciones requiere información adicional del cliente, el flujo se pausa, persiste su estado completo y espera. Cuando el cliente responde, la máquina de estados retoma exactamente desde donde estaba y la validación continúa. Al completarse, el estado se persiste y la máquina de estados avanza.
Es en este punto donde el flujo hace algo que ninguno de los tres modelos anteriores podía hacer limpiamente: reconoce que lo que sigue ya no le pertenece. La máquina de estados del núcleo transiciona al estado de control delegado y genera el identificador único de la transacción en curso. Ese identificador es lo único que el núcleo le entrega al módulo en el momento de la cesión. Con él, el módulo sabe a qué transacción pertenece cada uno de sus pasos. Y con él, puede consultar al núcleo cualquier información que necesite de la parte transversal ya completada.
A partir de ese instante, la máquina de estados del módulo toma el gobierno. El núcleo permanece en ese estado de espera activa, sin intervenir. Toda solicitud de navegación que llegue al núcleo durante este período es redirigida al módulo activo.
La máquina de estados del módulo activa sus pasos en la secuencia que ella misma define. Cada paso se ejecuta, produce un resultado y termina. Si un paso requiere interacción con el cliente, el flujo se pausa y espera exactamente igual que en la parte transversal. Después de cada paso, el estado se persiste y la máquina evalúa si hay un paso siguiente o si el módulo ha terminado.
Cuando no hay más pasos, el módulo devuelve el control al núcleo. La máquina de estados del núcleo transiciona desde el estado de control delegado hacia el cierre: registra la trazabilidad del flujo completo, persiste el estado final y notifica al cliente que el proceso ha concluido.
Lo que ve el cliente durante todo este proceso
Desde la perspectiva del cliente, el flujo es una secuencia continua de pantallas con un indicador de progreso que avanza. No hay ninguna señal visible de que en algún punto el gobierno pasó de una máquina de estados a otra. Esa continuidad no es cosmética: es el resultado de dos decisiones de diseño que trabajan juntas.
La primera es que el núcleo actúa como proxy de navegación. Toda instrucción del cliente, avanzar, retroceder, saltar a un paso anterior, cancelar, llega siempre al núcleo. El núcleo evalúa en qué punto del flujo se encuentra y decide si la ejecuta directamente o la redirige al módulo activo. El cliente nunca sabe esa distinción. Para él, siempre está hablando con el mismo interlocutor.
La segunda es que el indicador de progreso funciona sin necesidad de consultar al módulo en cada momento. El núcleo ya sabe cuántos pasos tiene el flujo completo desde el registro: el módulo declaró sus pasos al registrarse y esa información quedó almacenada de forma estática. Durante la ejecución, el núcleo solo necesita consultar al módulo por el paso actual, y únicamente cuando el control está delegado. El total de pasos nunca cambia y nunca necesita preguntarse de nuevo.
Con esas dos piezas en su lugar, cada pantalla puede ser completamente autónoma. No necesita conocer el flujo completo para saber qué mostrar ni con quién hablar. La navegación, avanzar, retroceder, saltar, cancelar, siempre pasa por el núcleo. Pero la interacción propia de cada paso, los datos que el cliente ingresa y las respuestas específicas de ese punto del flujo, van directamente al responsable de ese paso: el núcleo si el paso es transversal, el módulo si el paso le pertenece a él. Esto es posible porque cada pantalla es tan atómica como el paso que representa: desde el diseño se definen sus puntos de comunicación, con quién habla y para qué. No hay lógica en tiempo de ejecución que decida eso. La pantalla ya lo sabe.
Los comandos que el cliente puede dar en cualquier momento del flujo, y quién los resuelve, son los siguientes:
| Comando | Propósito | Quién resuelve la lógica |
|---|---|---|
| Consulta de pasos | Obtiene el total de pasos y el nombre de cada uno | Núcleo, usando el dato declarado en el registro del módulo |
| Consulta de progreso | Retorna el total de pasos, el paso actual y el último paso completado | Núcleo. Cuando el control está delegado, consulta al módulo por el paso actual |
| Siguiente | Avanza al siguiente paso lógico | Núcleo si el paso es transversal, módulo si el paso es del módulo |
| Atrás | Retrocede al paso anterior | Núcleo si el paso es transversal, módulo si el paso es del módulo |
| Salto | Navega a un paso específico, siempre que no supere el último paso alcanzado | Núcleo si el destino es transversal, módulo si el destino es del módulo |
| Cancelar | Termina el flujo completamente | Núcleo |
Lo que esta tabla muestra, más allá de los detalles técnicos, es que el cliente siempre tiene el mismo conjunto de comandos disponibles sin importar en qué parte del flujo se encuentra. El hecho de que algunos los resuelva el núcleo y otros el módulo es invisible para él. Y esa invisibilidad es exactamente lo que permite que el caso del banco, con sus dos productos distintos, se sienta como una sola experiencia coherente.
Lo que esta separación realmente cuesta
Sería deshonesto presentar este modelo sin nombrar lo que exige.
El contrato de extensión debe estar bien definido desde el principio. No en términos de la información que se transfiere en la cesión, que es mínima por diseño, sino en términos de las reglas de interacción: cómo se registra un módulo, qué debe declarar, cómo devuelve el control y qué formato tienen las respuestas que el núcleo espera. Si esas reglas están mal definidas o son ambiguas, los módulos las interpretarán de formas distintas y el flujo producirá comportamientos inconsistentes que son difíciles de rastrear porque la causa no está en la lógica de ningún paso sino en el acuerdo que los articula.
La máquina de estados de cada módulo requiere diseño cuidadoso. No es compleja en términos de implementación, pero sí requiere que quien diseña el módulo tenga claridad total sobre la secuencia de sus pasos, las transiciones válidas y los estados de pausa. Un módulo con una máquina de estados mal definida produce comportamientos inconsistentes que son difíciles de rastrear porque la lógica de secuencia está separada de la lógica de cada paso. Cuando algo falla, no es obvio si el problema está en el paso que se ejecutó o en la transición que lo activó.
Los endpoints que el núcleo expone para que los módulos consulten información transversal deben tratarse con la misma disciplina que el contrato de extensión. Son una interfaz pública que los módulos van a consumir, y cualquier cambio en ellos tiene el potencial de romper módulos existentes. Agregar endpoints nuevos es seguro: los módulos que no los necesitan simplemente no los usan. Pero modificar o eliminar endpoints existentes requiere coordinación con todos los módulos que los consumen, y esa coordinación tiene un costo real que crece con la cantidad de módulos operativos.
El modelo de proxy de navegación en el núcleo introduce una dependencia en tiempo de ejecución que debe estar bien resuelta. Cuando el núcleo redirige una solicitud de navegación al módulo activo, necesita tener una referencia válida a ese módulo. Si el módulo no está disponible por cualquier razón, esa solicitud falla. Esto no es diferente a cualquier otra dependencia en tiempo de ejecución, pero debe tenerse en cuenta en el diseño de tolerancia a fallos del sistema.
Finalmente, la disciplina de no modificar el núcleo es una restricción organizacional además de técnica. En la práctica, siempre hay presión para agregar una excepción aquí, un comportamiento especial allá. Cada vez que esa presión cede, el núcleo pierde algo de su estabilidad y el modelo empieza a degradarse. Mantener esa disciplina requiere que el equipo entienda bien por qué el núcleo es cerrado a modificación, no solo que sepa que lo es.
Todo ese costo tiene un punto de equilibrio. Si el sistema tiene un solo tipo de caso y es poco probable que eso cambie, el modelo agrega complejidad estructural sin beneficio real. La separación entre núcleo y módulos, las dos máquinas de estados, el contrato de extensión, los endpoints de consulta: todo eso se justifica cuando hay variabilidad real entre casos, cuando el comportamiento transversal necesita mantenerse consistente y evolucionar de forma independiente, y cuando la incorporación de nuevos casos debe ser posible sin riesgo sobre lo que ya está operando. Cuanto más de esas tres condiciones se cumplen, más sentido tiene asumir la exigencia que el modelo impone.
De vuelta al banco
Con el modelo completo sobre la mesa, el caso del banco deja de verse como un flujo de productos financieros y empieza a revelar el problema arquitectónico que realmente estaba presente desde el principio.
La dificultad nunca fue únicamente validar identidad, consultar historial crediticio o pedir documentos distintos según el producto. Eso podía resolverse de muchas maneras. El problema real era otro: cómo permitir que el sistema creciera sin que cada nuevo producto aumentara el acoplamiento, duplicara lógica o volviera más frágil el flujo completo.
Cuando el núcleo concentra únicamente las responsabilidades transversales y los productos viven en módulos independientes con su propia máquina de estados, el crecimiento deja de sentirse como una modificación del sistema existente y empieza a comportarse como una extensión controlada. Nuevos productos pueden incorporarse sin intervenir los flujos que ya operan, los equipos dejan de depender entre sí para evolucionar casos específicos y la complejidad deja de acumularse en un único lugar.
Hoy existen dos productos. Mañana habrá créditos hipotecarios, productos empresariales, validaciones regulatorias nuevas y recorridos especializados que todavía no existen. Cada uno traerá lógica distinta, pasos distintos y reglas distintas. Pero todos seguirán compartiendo la misma necesidad transversal: entender quién es el cliente antes de tomar cualquier decisión.
El valor del modelo no está en resolver bien los dos productos actuales. Está en evitar que el tercer producto convierta al sistema en algo más difícil de modificar que el segundo. Está en permitir que la variabilidad crezca sin que el núcleo pierda estabilidad. Está en separar la evolución de los productos de la evolución del flujo transversal.
Las tres soluciones iniciales parecían razonables mientras el sistema era pequeño. Duplicar lógica, centralizar mediante invocaciones directas o resolver todo con condicionales podían funcionar durante un tiempo. El problema aparecía después, cuando cada nuevo caso hacía que el sistema completo fuera más difícil de entender, probar y evolucionar. La pregunta que el banco se hacía al principio, dónde vive el comportamiento compartido, no tenía una respuesta técnica. Tenía una respuesta arquitectónica. Y la diferencia entre las dos es exactamente lo que determina si el cuarto producto se incorpora con la misma facilidad que el segundo o si para entonces ya nadie quiere tocar ese código.


























